

Archive for the 'Bit Bucket' Category
AVR-GCC Compiler Makes Questionable Code
Most people believe that modern compilers generate better-optimized assembly code than humans, but look at this example from AVR-GCC 5.4.0 with -O2 optimization level:
7b96: 10 92 34 37 sts 0x3734, r1 ; 0x803734 <tachFlutter>
7b9a: e0 e0 ldi r30, 0x00 ; 0
7b9c: f0 e0 ldi r31, 0x00 ; 0
7b9e: a0 91 35 37 lds r26, 0x3735 ; 0x803735 <driveTachHalfPeriod>
7ba2: b0 91 36 37 lds r27, 0x3736 ; 0x803736 <driveTachHalfPeriod+0x1>
7ba6: ae 1b sub r26, r30
7ba8: bf 0b sbc r27, r31
7baa: b0 93 89 00 sts 0x0089, r27 ; 0x800089 <OCR1AH>
7bae: a0 93 88 00 sts 0x0088, r26 ; 0x800088 <OCR1AL>
7bb2: 10 92 95 00 sts 0x0095, r1 ; 0x800095 <TCNT3H>
7bb6: 10 92 94 00 sts 0x0094, r1 ; 0x800094 <TCNT3L>
7bba: 32 2d mov r19, r2
7bbc: e0 e0 ldi r30, 0x00 ; 0
7bbe: f0 e0 ldi r31, 0x00 ; 0
7bc0: f0 93 e3 33 sts 0x33E3, r31 ; 0x8033e3 <currentTrackBytePos+0x1>
7bc4: e0 93 e2 33 sts 0x33E2, r30 ; 0x8033e2 <currentTrackBytePos>
This is straight-line code with no branching. All registers and memory references are 8-bit. With AVR-GCC, the register r1 always holds the value 0, so the code is doing this: Set tachFlutter to 0, load driveTachHalfPeriod, set OCR1A to driveTachHalfPeriod minus 0, set TCNT3 to 0, set currentTrackBytePos to 0. There’s also a move of r2 to r19, which is used later, and I’m not sure why the compiler located the instruction here. There are at least three glaring inefficiences:
- the compiler wastes time loading 0 into r30 and r31, when it could have just used r1
- it does this TWICE, when we know r30 and r31 were already zero after the first time
- it subtracts a constant 0 from driveTachHalfPeriod
I can maybe understand the subtraction of constant 0, if there’s another code path that jumps to 7ba6 where the value in r30:r31 isn’t 0. But why wouldn’t the compiler make a completely separate path for that, with faster execution speed when the subtracted value is known to be 0, even if the code size is greater? After all this is -O2, not -Os.
It also appears there’s no optimization for setting multi-byte variables like currentTrackBytePos to zero. Instead of just storing r1 twice for the low and high bytes, the compiler first creates an unnamed 16-bit temporary variable in r30:r31 and sets its value to 0, then stores the unnamed variable at currentTrackBytePos.
This whole block of code could easily be rewritten:
sts 0x3734, r1 ; 0x803734 <tachFlutter>
lds r26, 0x3736 ; 0x803736 <driveTachHalfPeriod+0x1>
sts 0x0089, r26 ; 0x800089 <OCR1AH>
lds r26, 0x3735 ; 0x803735 <driveTachHalfPeriod>
sts 0x0088, r26 ; 0x800088 <OCR1AL>
sts 0x0095, r1 ; 0x800095 <TCNT3H>
sts 0x0094, r1 ; 0x800094 <TCNT3L>
mov r19, r2
sts 0x33E3, r1 ; 0x8033e3 <currentTrackBytePos+0x1>
sts 0x33E2, r1 ; 0x8033e2 <currentTrackBytePos>
This is much shorter, and avoids using r27, r30, and r31, so there are more free registers available for other purposes.
Read 17 comments and join the conversationRon Nicholson, Early Mac and Amiga Engineer

Tonight I’ll be attending a presentation from Ron Nicholson, who was both a member of the original Macintosh engineering team (1980-1982) and founder and Director of Engineering of Amiga (1983-1984). I believe he’s the only person whose signature is molded into the case of the early Macintosh and the original Amiga computers. Post your questions for Ron here, and I’ll try to get answers, or see if I can entice him to come here and answer them himself.
Among his many accomplishments, at Apple Ron was an IWM ASIC project engineer and Apple II peripheral engineer, including work on the Super Serial Card. He also worked on the CMOS clock chip for the original Macintosh. Ron has worked at several Silicon Valley companies, including Apple, Amiga, HP, Sigma Designs, and Silicon Graphics. Ron has contributed to the design of FPGAs, network ASICs, RISC workstations, the Nintendo 64, the original Apple Macintosh, and the Commodore Amiga. Ron is named as co-inventor on 11 U.S. patents, including several on the architecture of the Amiga 1000. http://www.nicholson.com/rhn/index.html
Read 3 comments and join the conversationFirst Look at the RP2040 – Raspberry Pi Microcontroller

In response to my last post, a few readers suggested looking at the Raspberry Pi Foundation’s RP2040 microcontroller for possible use in a future Floppy Emu hardware refresh. The RP2040 was announced in January 2021, first as part of the Raspberry Pi Pico development board, and later as a stand-alone chip. While Raspberry Pi’s other offerings are essentially full-fledged computers, the RP2040 is a traditional microcontroller that will compete directly with familiar products from Microchip, ST, Espressif, and NXP. So what does it offer that might set it apart from the competition? Is it worth a look? Here’s my take.
Strong Points
RP2040 is a 133 MHz dual-core ARM Cortex M0+ microcontroller, with 264 KB of RAM, and a unit price of $1 USD. Right off the bat, that looks appealing. I don’t know of any other microcontroller from a major vendor that offer a better ratio of hardware specs per dollar. 133 MHz is quite zippy, and 264 KB of RAM is substantially more than any of the alternative parts I’ve been considering. Dual core is just icing on the cake.
The hardware also includes two programmable I/O (PIO) blocks with interesting potential. These are hard to describe in a single paragraph, but they’re like high-speed specialized coprocessors that could replace much of the software-based bit-banging that’s often needed in microcontroller applications. They’re a good fit for high-speed bit twiddling, independent of the main cores. For the Floppy Emu, PIO blocks could probably be used to replace some of the specialized logic that’s currently handled by a CPLD programmable logic chip.
The documentation looks well-written. So far I’ve reviewed the chip datasheet, hardware design guide, the C/C++ SDK documentation, and the Getting Started Guide.
The RP2040 is available and shipping in large quantities right now, which is quite an accomplishment given the current shortages everywhere else in the industry. DigiKey has over 50000 in stock. You can also order the chips directly from Raspberry Pi.
Weak Points
There’s zero flash or non-volatile memory for program storage on the RP2040. All the application code and data must be stored in an external flash chip. Six dedicated pins are used to communicate with a separate QSPI flash, using execute-in-place (XIP) technology to run code directly from flash without needing to copy it to RAM first. A 16 KB XIP cache helps speed up this process. Relying entirely on external flash helps keep the RP2040 price down, and lets the user choose a flash chip whose storage size matches their needs, but it also has some serious drawbacks for my purposes.
The biggest worry is code execution speed. If most of the code fits into the 16 KB cache, then the code should run as fast as any other CM0+ microcontroller with similar specs. But for uncached code, and especially for application startup code when nothing is yet cached, I fear it will be slooooow, slower even than 8-bit AVRs with much lower system clock speeds. I used section 2.3 of this Atmel document to understand what XIP traffic looks like for a QSPI interface. Fetching a 32-bit value requires 20 SPI clocks, which is 80 system clocks using the RP2040’s default settings. A 32-bit value can hold two 16-bit Thumb instructions, so it looks like 40 system clocks per instruction, or 3.3 MIPS at 133 MHz. Slow.
For many time-critical routines, code can be pre-loaded into RAM with some extra effort, where it will run much faster. But for application startup code there’s really no way around this bottleneck. I’m not sure if this would be a serious problem, or if I’m worrying over nothing.
There’s no easy place to store settings information, like the EEPROM on an AVR. Presumably settings would need to be stored in the same external flash as the program code. This would require copying some section of code to RAM and executing it, which would deactivate the XIP interface and use standard SPI flash commands to update a few bytes, before re-enabling XIP and resuming the program.
The RP2040 bootloader could be considered both a strong point and a weak one. There’s a built-in USB bootloader in mask ROM, which is activated if the external flash is missing or deactivated. To the computer it appears as a USB mass storage device, so you can update the firmware with a simple drag-and-drop. This is great if your product already has a USB device (USB-B) connector on it, but the Floppy Emu doesn’t and doesn’t need one. I could roll my own pseudo-bootloader as part of the main application code, to load firmware updates from the SD card, but it wouldn’t be in protected memory like a real bootloader. If something went wrong during the update, it might corrupt the pseudo-bootloader and effectively brick the device.
While I admit I haven’t tried it, the C/C++ development toolchain doesn’t look great. Ideally I’d hope to see an IDE like Atmel Studio or STM32 Cube, with hardware-specific tools to help configure the peripherals, GUI settings for all the build options, an integrated simulator and debugger, and so on. But the reality is more like a pile of libraries, header files, and build scripts. Changing any kind of build settings relies heavily on editing CMake files and adding new defines whose existence you may not have known about. Sure you can use the VSCode IDE, but it doesn’t seem to do much more than function as a text editor, and you’ll still be tearing your hair out struggling with CMake. The build environment is also clearly geared towards Linux, and while setup is possible under Windows, it appears to be cumbersome.
My last worry is over the RP2040 development community, or really the lack of a community. If you’re developing for an AVR, or Atmel SAM, or STM32, you’ll find thousands of helpful resources on the web with example code, discussion forums, and sample projects. There’s very little of this for RP2040, and most of what does exist is geared towards Micro Python and Circuit Python, rather than bare metal C/C++ development. The only discussion forum I’ve found is a small subsection of the main Rasperry Pi forums. This doesn’t make it impossible to develop – the documentation seems thorough and there is some help on the web. But it’s a far cry from working “in the herd” and developing for a more popular microcontroller family.
Conclusions
So is the RP2040 the future of the Floppy Emu? It’s hard to say, but I think probably not. It may help to compare it against some other possibilities, like the Atmel SAMD21 (48 MHz CM0+ with 32 KB RAM) or SAMD51 (120 MHz CM4 with 128 KB RAM), which cost around $4 each in large quantities. Compare these to an RP2040 plus an external flash chip, with a combined cost of about $2. The RP2040 solution is half the price, but both alternatives are cheap enough, and I would choose whatever solution will make development easiest.
The extra RAM of the RP2040 is welcome, but I’m unsure what I’d do with it. 32 KB is more than enough to buffer a disk track plus other application data, and unless I had 1MB or more to buffer a whole disk, additional RAM might not be immediately useful.
133 MHz is greater than 48 MHz, so maybe the RP2040 is much faster than the SAMD21? Or maybe not, given the overhead of XIP code execution?
All these differences in favor of the RP2040 look interesting, but if they aren’t critical for my specific application, then are they worth the trade-offs of the build environment, development community, and concerns about external flash?
For the specific case of the Floppy Emu, I think the best argument in favor of the RP2040 is the PIO blocks. If those could replace all of the logic that’s currently handled by a CPLD programmable logic chip, then I could eliminate the CPLD entirely, and greatly simplify the whole design. But if the PIO blocks can only replace some of the logic, then I still need a CPLD or something similar, and the advantage of the RP2040 is much less. But that’s a difficult question to answer by just reading the docs, and I’d need to really dig in and try building it.
Read 32 comments and join the conversationThe Amazing Disk II Controller Card

In the world of Apple II disks, there are two major types of disk controller cards: the original Disk II controller (and clones), and everything else. Both have their place. The “everything else” category includes the Apple 3.5 disk controller card, Liron card, SCSI cards, IDE cards, and more. These cards provide a standard API for software to read/write blocks, get drive status, and format the disk, all without requiring the software to know anything about how the disk actually works. These cards have built-in smarts to handle the low-level details. In contrast the original Disk II controller card is dumb as dirt, and forces the software to handle virtually all of the low-level details. And yet it’s an amazing piece of technology for its time.
The first Apple II models had no built-in floppy disk support. The Disk II controller was cleverly designed to add that missing support at a very low cost, and was a major reason why Apple II computers became so popular. This disk controller was simpler, and cheaper, and more flexible, and just all-around better than any of its contemporary competition. It’s the ultimate example of Woz can-do technology.
Floppy Disk 101
A floppy disk is just a plastic circle with a magnetic coating. Loaded into a drive, the disk rotates at about 300 RPM. A stepper motor moves the read/write head linearly from the center of the disk to the outer rim. This arrangement provides for a few dozen concentric rings where a serial stream of 1s and 0s can be stored.

How do you get from these basics to higher-level concepts like bytes, tracks, and sectors? How are logical data bytes encoded into bit patterns on the disk? When reading the disk, how are the bits framed into bytes? How do you find track zero, or the boundaries between sectors? The conventional answer to these questions in the 1970s was extra hardware, and lots of it. This made the disk controllers and the drives themselves complex and expensive, putting them mostly out-of-reach for an inexpensive home computer system.
It was late 1977 when Apple set its sights on finding an alternative to cassette tape data storage, and began looking into options for a floppy drive for the Apple II. They were still a small and unproven company, and the Apple II had only been available for about six months. Woz didn’t know much about the subject of floppy disks, but he agreed to take on the challenge.
Woz’s approach was to remove virtually all of the hardware that controls the disk, and take a software-driven approach akin to bit-banging. Apple went to Shugart, the inventors of the 5.25 inch floppy drive, and requested a stripped-down version of Shugart’s SA400 drive with most of the control electronics removed. It was just a simple mechanism with one motor for spinning the disk and a stepper motor for moving the read/write head. As the legend goes, the entire Disk II hardware design was conceived and built by Woz and Randy Wigginton over a few weeks during Christmas vacation 1977, including writing the first version of DOS, and the working disk drive was demoed at CES in January 1978. Additional help was provided by Apple engineers Cliff Huston and Wendell Sander. 40+ years later I’m amazed by how quickly this small team was able to make everything work.
A few years ago I asked Woz about the Disk II development, and he said this:
I have no idea how I came up with that incredible disk controller. I was good at creating anything in electronics, analog or digital. I had no prior experience of any kind, not even in classes, regarding disk hardware or software. So my thinking had to be from the ground up. I had to sense data coming from the disk and make decisions about 0’s and 1’s based on timing.
I had taken a graduate level course at Berkeley (although an undergrad, I only took grad courses in anything having to do with computers in any university) on state machines and thought of how I could use 2 simple low cost chips as a state machine to do this, sort of a minimal microprocessor hand-built. At the time I just knew that it would read and write data but I assumed that I was leaving out many ingredients of a disk controller due to not knowing what they did. I assumed this because my design took so few parts. But in the end, mine did more in some good ways, especially since it was in the computer and tied to software that could alter how it worked, which eventually led to greater storage and faster speed that would not have been possible using the normal disk. Plus, I took about 20 chips off the drive itself and bypassed them from my own controller, because they were just middlemen that got in the way of things.
The best work I did, over and over, was partly due to not having money and having to learn how to use the fewest parts of anyone, and also due to the fact that everything great I created I had never done before.
A Tour Of The Disk II Controller
The Disk II controller card is basically just a fancy shift register. It knows how to read and write bits at a fixed rate of 1 bit every 4 microseconds. The card also has a tiny 256 byte ROM containing bootstrap code that runs when the computer first turns on. It’s a minimal 6502 program with just enough smarts to locate track 0, sector 0, load it into the computer’s memory, and then execute it. Every other aspect of disk control is handled by software.
The card contains only eight simple chips. There’s a 256 byte ROM containing the bootstrap code, and a second 256 byte ROM used as part of a state machine (more on this in a moment). There’s also a 74LS174 hex flip flop providing the inputs for the state machine. A 74LS323 eight bit shift register is the heart of the whole design. A 74LS259 addressable latch stores the desired state of the motors and the drive 1 or 2 selection. There’s a 556 dual timer, and a 74LS05 hex inverter and 74LS132 quad NAND to provide some needed glue logic. That’s it. That’s the entire disk controller. Here’s the schematic:
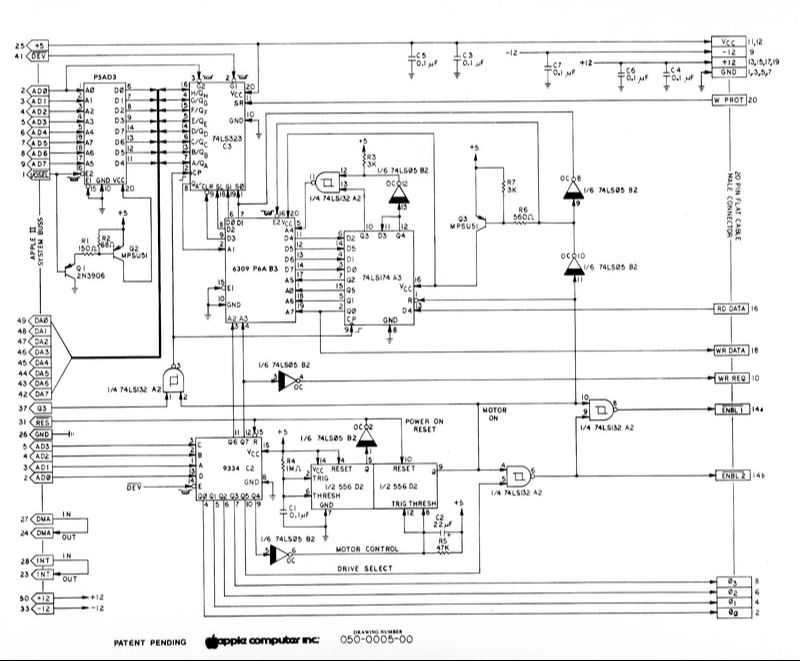
Let’s go through the challenges of floppy disk I/O one at a time, and look at how the Disk II controller design solved them.
Challenge #1: byte framing. The data coming from the disk is a continuous stream of 1s and 0s, and there are no start or stop bits. So how do you know where one byte ends and the next byte begins? Woz’s solution was to require that every byte written to the disk have 1 as the most significant bit. During a disk read, the state machine takes bits from the disk one at a time, moving the shift register one position left and appending the new bit at the right. It keeps going until the left-most bit position holds a 1, at which point the state machine says “Aha! Here is a complete byte!” Then the CPU stores the byte, and the process begins again. The state machine clears the shift register after the MSB becomes 1, so it’s ready to shift in the eight bits for the next byte.
By itself this solution isn’t enough. If the state machine starts reading bits in what was actually the middle of a byte, it will probably misinterpret a 1 bit in the middle of the byte as being the 1 bit for the MSB position. But this scheme ensures that if the state machine gets the byte framing correct just once, whether by luck or another method, it will continue to be correct from then on. So the challenge is finding a way to guarantee the framing is correct before beginning to read disk data.
The conventional solution is to write a special 50-bit pattern of so-called sync bytes to the disk, immediately before each sector. These aren’t really bytes at all, but a 10-bit pattern 1111111100 repeated five times. This pattern has the interesting property that no matter where the byte framing is initially, it will fall into correct synchronization after at most five repetitions of the pattern, just by following the state machine rules described previously. This solution is entirely software-driven, and is merely a convention. The hardware itself has no mechanism to guarantee correct byte framing. There are other methods of ensuring framing, and some of the bizarre richness of Apple II copy-protection schemes arises from different approaches to framing taken by the custom I/O routines in many games.
Challenge #2: byte encoding. If every byte written to disk must have 1 as the MSB, then how do you write a zero byte, or any other byte with a value less than 128? And there are other restrictions too: every byte written to disk must have no more than two consecutive zero bits. If there are three consecutive zero bits, the disk hardware can’t reliably read back the data. Given these two requirements, there are only 66 possible 8-bit values that are permitted to be written to the disk. How then can arbitrary 8-bit values be stored?
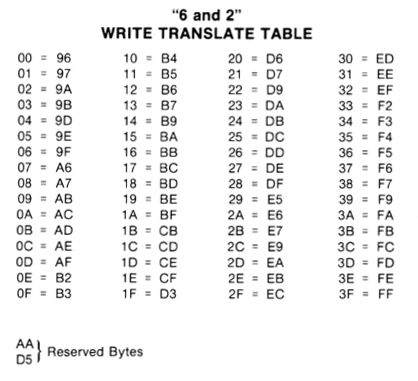
The answer is to split up the logical 8-bit bytes, and store their bits in subgroups as part of multiple disk bytes. The standard way of doing this is a GCR encoding scheme called 6-and-2. With 66 possible values for the disk byte, and two reserved values, that leaves 64 possible disk bytes for encoding data. 64 is 2 to the 6th power, so six logical bits can be encoded in every disk byte. A series of three disk bytes can encode the first six bits of three logical bytes, and a final fourth disk byte can encode the last two bits of the three logical bytes, concatenated together. This means the number of bytes stored on disk is 4/3 times the number of logical bytes, ignoring headers and checksums and padding.
You might wonder how the Disk II controller bootstrap code accomplishes the GCR decoding for sector 0, track 0. At first glance, it would seem to require storing a 64-entry reverse lookup table in ROM, which is already one quarter of the very limited ROM space available. The bootstrap code actually uses a much cleverer solution, and constructs a 256-entry forward lookup table in RAM on the fly, using only 30 bytes of 6502 code!
The Apple II floppy byte encoding has evolved over time, resulting in a changing number of sectors and total disk capacity. The first version of the Disk II controller card didn’t permit any consecutive zeroes to be written to the disk. This further limited the number of possible disk bytes, and forced the use of a less efficient 5-and-3 encoding scheme. It was only possible to fit 13 sectors per track, resulting in 114 KB total disk capacity. Apple DOS 3.1 and 3.2 used the 5-and-3 scheme. Eventually Woz or one of his teammates realized that with a small change to the state machine, it would be possible to read two consecutive zeroes reliably. All it required was a change to the contents of the state machine ROM, essentially fixing a small bug in order to make the bit timing measurements more reliable. No hardware changes were needed to the Disk II controller. The more efficient 6-and-2 scheme was introduced beginning with DOS 3.3, ushering in the 16 sector tracks and 140K disks we’re familiar with now.
As with the byte framing, this whole encoding scheme is purely a software convention. There’s nothing about the hardware that implements 6-and-2 or 5-and-3 or any other encoding method. Sector 0 track 0 must be encoded using 6-and-2, because that’s what the ROM bootstrap code expects, but after that anything goes. Software is free to use any other encoding scheme it wishes, and many copy-protected programs use novel encoding schemes in order to obfuscate their workings.
Challenge #3: sectoring. Once you’ve got the bitstream correctly framed into disk bytes, and the disk bytes correctly decoded into logical bytes, how do you make any sense of the data? It’s a ring buffer, so how do you know where the data begins and ends? 1970s floppy disks often used one or more small holes punched in the disk at regular intervals around the circumference. A small opening was cut in the disk’s dust jacket in order to reveal the index holes as they passed underneath. Hardware inside the disk drive sensed when these holes passed by as the disk rotated, and this information was used to determine where a new track or new sector began.
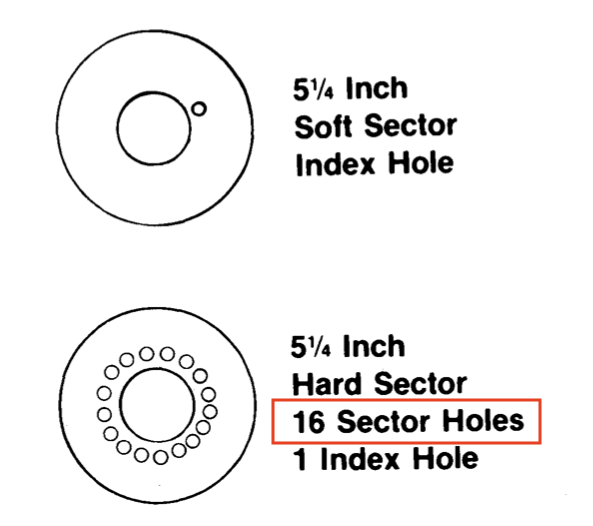
It’s easy to see why this might be undesirable. The hole-sensing hardware adds extra complexity and cost. And in the case of hard-sectored floppies with a hole for every sector, the number of sectors becomes part of the hardware design and can’t be changed. Apple’s move from 13-sector to 16-sector format would have been impossible with hard-sectored disks.
The Disk II design takes a software-driven approach to sectoring. Any index holes on the disk are ignored. When it wants to find a particular sector on the current track, the computer begins reading bytes, ignoring everything it sees until it finds the three-byte sequence D5 AA 96. This signature marks the beginning of a new sector on the disk, and is possibly the most famous byte sequence in the entire kingdom of Apple II arcana. On the wall of my office hangs a 5.25 inch floppy disk with a D5 AA 96 greeting signed by Woz himself:

A short sector header follows this signature, and among other things the header contains the sector number. If it’s the sector number the computer was looking for, then it reads the bytes that follow. If it’s not the right sector, then it keeps looking for another D5 AA 96 to indicate the beginning of the next sector, and tries again.
This whole business is – you guessed it – purely a software convention. The D5 AA 96 signature, the sector header, the length of sectors, and everything else are merely conventions. There’s nothing whatsoever about the Disk II controller card hardware that requires software to work this way, and some software takes a different approach. One well-known example was the game Prince of Persia, which used a custom scheme called RWTS18 that was optimized for reading as opposed to writing, and used six 768-byte sectors per track instead of the standard sixteen 256-byte sectors.
Challenge #4: finding tracks. So far we’ve only discussed data in a single one of the concentric rings on the disk. These rings are usually called tracks, but as we’ll see, the definition of exactly what constitutes a track can sometimes be fuzzy. So how do you switch between tracks, or locate a specific track? And just how many tracks are there? The Disk II and its controller hardware don’t answer these questions. Instead, it’s all (say it with me now) software-driven.
On the disk media there’s no such thing as a track – it’s just a featureless round expanse of magnetic media. Tracks are created when the read/write head remains at a fixed radial position while the disk spins underneath and bits are written. Then the head moves inward or outward to a new radial position, and writes a new track.
The head movement is controlled by a stepper motor, under direct software control. The stepper consists of four electromagnets, and at any moment the software can turn any of them on or off. A series of permanent magnets are attached to a gear that moves the read/write head, and by activating the electromagnets in the right sequence, they can attract or repel the permanent magnets and move the head. If stepper electromagnet 0 was on, and then electromagnet 1 is turned on and electromagnet 0 turned off, the head will move a small radial distance. Then if electromagnet 2 is turned on and electromagnet 1 turned off, the head will move further in the same direction.
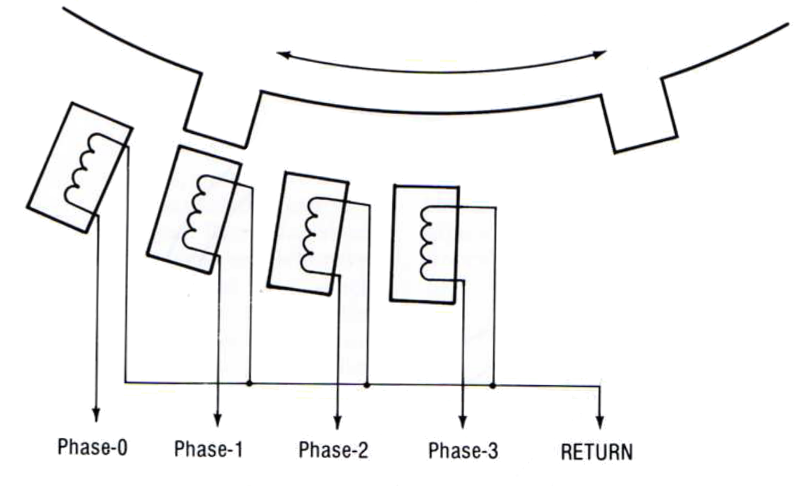
How closely can you space the tracks? It turns out that two of these head movements are normally needed in order to move the head far enough so that a track won’t interfere with its neighbors. If you try to write tracks with only one head movement between them, the magnetized areas of the disk media from the adjacent tracks will bleed into each other and cause a mess. For this reason, two movements are normally considered to be equal to one track, and a single movement is a half track. Quarter tracks are also possible, but aren’t used by most software. If electromagnet 0 was on, and then electromagnet 1 is also turned on, the head will move a quarter track. If electromagnet 0 is then turned off, the head will move an additional quarter track.
The method of locating track 0 is as crude as can be. The disk controller doesn’t know at what track the read/write head is currently located, so software must activate the stepper motors in sequence in order to move the head continuously in the direction of track 0. Eventually the head will reach track 0 and can move no further, but the software will keep activating the stepper motors, driving the head against a mechanical stop and producing the familiar rat-a-tat sound of an Apple II floppy drive during boot-up. After 80 half steps, the head is guaranteed to be at track 0. From that point on the software must keep track of all stepping movements, and remember what track the head is currently on, in order to perform relative steps. If the software gets confused, say by reading what it thinks is track 20 but finding data for a different track there, it will usually recalibrate by repeating the track 0 seek and then immediately stepping back to the desired track. This creates a clack-clack sound that many long-time Apple II users will recognize as the sign of a failing disk.
It’s customary to store 35 tracks per disk, but this is merely a convention. The true limit varies slightly from one drive to the next, and is determined by the maximum and minimum linear positions of the read/write head. Non-standard disks with up to 40 tracks are sometimes seen.
Copy-protected Apple II games very often play funny tricks with track stepping. A simple trick is locating a track at some odd number of half-steps from track 0. Tracks must be at least two half steps apart, but there’s no rule saying they can’t be three half steps apart, so you might find a game disk with data on tracks 0, 1, 2.5 and 4. This will confuse disk copy programs that only expect to find data on integer numbered tracks.
A more advanced trick is writing data on two tracks that are just a half step apart, but only using half the circumference of the disk for each track, so the magnetized areas won’t interfere with each other. There might be a half-track’s worth of data at track 2 from twelve o’clock to six o’clock around the disk, and then another half-track’s worth of data at track 2.5 from six o’clock back around to twelve o’clock. Data that’s written this way is easy to read, but is difficult to write without specially-crafted routines, making disk copies difficult.
Bootstrap Code Disassembly
A disassembly and analysis of the 256-byte bootstrap routine is fascinating. Starting with literally nothing, this code must bang directly on soft switches to control the stepper and read the shift register. It must activate the stepper electromagnets in the right pattern to reach track zero, and then begin reading bytes. It must recognize the D5 AA 96 signature, and check to see if it has the right sector. It must use a GCR decode table which it constructs on-the-fly in order to convert disk bytes. It must perform 6-and-2 decoding to reconstruct three logical bytes from four disk bytes, load the whole sector into a RAM buffer, and then jump to the just-loaded code. And all of this in only 256 bytes!

Woz gets the job done with five bytes to spare, and only about 100 lines of 6502 assembly code. But due to space constraints, some features were omitted. The Disk II controller bootstrap code doesn’t verify the checksum on sector 0, something that was “fixed” in later disk controllers but caused incompatibility with some games. There’s also no error handling, so the bootstrap code will keep trying forever to load sector 0. This explains why an Apple II with Disk II controller card appears to hang during booting if there’s no disk in the drive, or a bad disk, rather than show a nice error message like the Apple IIc or IIgs.
Disk II Controller Hardware Design
This discussion has focused on what the Disk II controller does, without going into much detail about precisely how it does it, and how those eight chips are used. For an excellent and very thorough breakdown I recommend reading Chapter 9 of Understanding the Apple II by Jim Sather. It goes into additional detail about the flux patterns on the disk and much more.
The design of the state machine is quite interesting, and I haven’t seen it described anywhere other than in Sather’s book. Anyone who remembers concepts like Mealy and Moore state machines from a long-ago class will recognize Woz’s work. The state machine ROM is just a simple lookup table. Its inputs are the current state, the read/write mode, the MSB of the shift register, and the next bit coming from the disk. The outputs are the next state and a set of control signals. Depending on the control signals, the state machine may shift the value in the shift register and append a zero or one bit, or clear the shift register, or parallel load the shift register from the data bus.
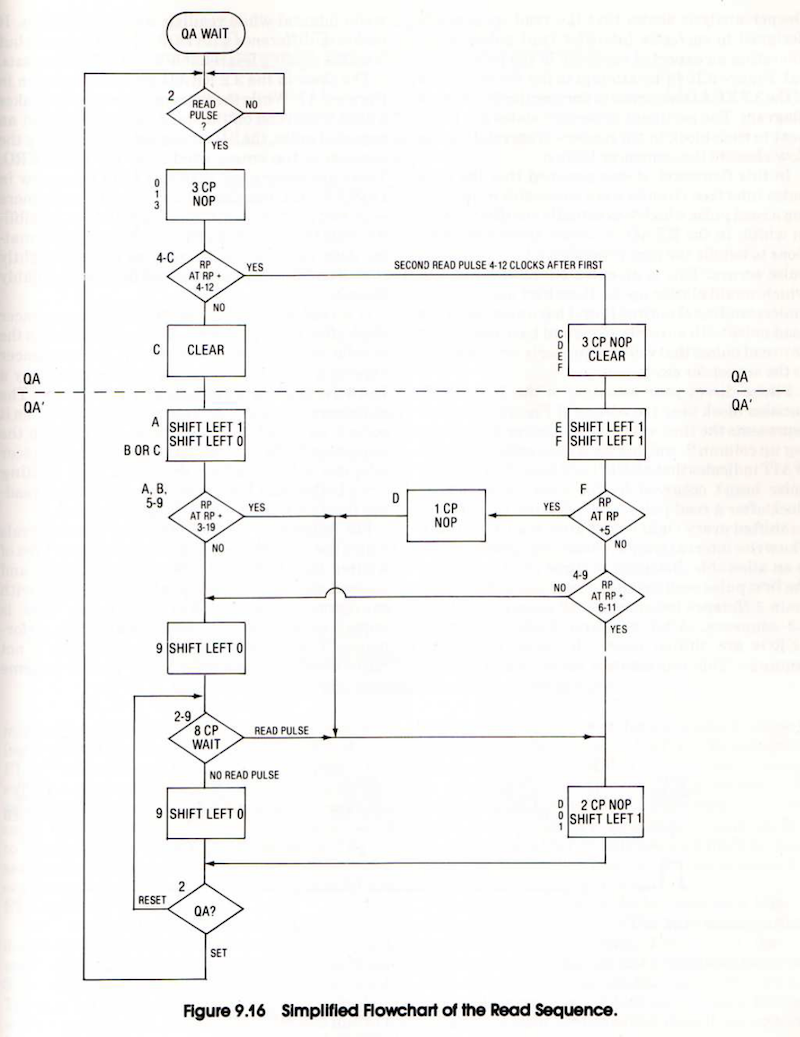
The state encodings are carefully chosen such that state bits can double as control bits. For example, when writing data to the disk, the value on the write head is also the most significant bit of the current state number. When reading data from the disk, the state sequences are chosen so as to frame pulses corresponding to 1 bits into an appropriate 4 microsecond window, and insert zero bits whenever 1.5 bit windows (6 microseconds) have elapsed without seeing a pulse. For my Yellowstone FPGA-based disk controller I’ve implemented the equivalent functionality in a hundred lines of Verilog; Woz did it with a 256-byte ROM and a hex flip-flop.
Putting It All Together
The words “software-driven” have come up again and again here, and that’s the theme of the Disk II controller. It enables a very flexible design using minimal hardware, but it pushes a tremendous amount of complexity onto the software. Modern software designers might call this bad practice, and would prefer to see that complexity abstracted away behind a standard interface, so the software only has to be concerned with actions like “read block 31”. And that’s exactly how all other Apple II disk controllers work. But in order to work with a Disk II controller, software like DOS 3.3, ProDOS, and most games need to include tons of extra code for manipulating the stepper, locating sectors, performing GCR decoding, and the whole kitchen sink. It’s a little bit crazy, but it works.

If you’ve read this far, you may be interested in the BMOW Floppy Emu disk emulator. Collectors of old Apple II, Macintosh, or Lisa computers will find the Floppy Emu invaluable for running software downloaded from the web, and transferring files between vintage and modern machines. The Floppy Emu stores hundreds of disk images on an SD memory card, and uses custom hardware to mimic many different kinds of Apple floppy disk drives and hard drives. Read more about it here.
During the 10+ years I’ve spent delving into every aspect of Apple’s disk drive designs, it’s been a remarkable journey. Years ago I used to think I understood how it all worked, but today I realize I hardly knew anything at all. Now I believe I’ve got everything mapped out, but of course there are probably still holes in my understanding that I’m blind to. Did I explain anything incorrectly here, or forget to mention something important? Let’s hear about it. Please leave a comment below.
Read 10 comments and join the conversationWordPress Latin1 and UTF-8, Part 2

Yesterday I wrote about some BMOW blog troubles displaying special characters and international characters, which was apparently triggered by a recent update to MySQL 8 at my web host. Old pages containing special characters like curly quotes, accented letters, or non-Latin characters were suddenly rendering as garbled combinations of random-looking symbols, whereas they were previously OK. If you read the follow-up comments, you saw that I was eventually able to resolve the problem (mostly) by adding these lines to my wp-config.php file:
define(‘DB_CHARSET’, ‘latin1’);
define(‘DB_COLLATE’, ”);
But I didn’t fully understand what those lines changed, or exactly why this problem appeared in the first place. After some digging in the MySQL database, I think I have a slightly better understanding now.
Back to Kristian Möller
I returned to the example of Kristian Möller, whose name contains the letter o with umlaut. After the MySQL update, the name was appearing incorrectly as Möller. This is what you’d expect to see if the UTF-8 bytes 0xC3 0xB6 for ö were incorrectly interpreted as two separate Latin1 bytes, 0xC3 for à and 0xB6 for ¶.
Using phpmyadmin, I was able to connect to the live WordPress DB, and examine the wp_comments table where this name is stored. The result for comment_id 233746 is shown above, displaying the author’s name as both text and as raw hex bytes. You can see the hex bytes contain the sequence C3B6, which is the correct UTF-8 byte sequence for ö. That’s great news. It means the contents of my database text are correct and uncorrupted UTF-8 bytes. But all is not well – the metadata associated with the table is wrong. It thinks the text is Latin1, and displays it as such in the myphpadmin UI. I was able to confirm this by executing the SQL command:
show create table wp_comments
This echoes back the SQL command that was originally used to create this table, way back in 2007. And lo and behold, part of that original SQL command specified CHARSET=latin1. Ever since then, WordPress has been storing and retrieving UTF-8 text into a Latin1 table in the database. This is bad practice, but it worked fine for 14 years until the MySQL update earlier this month.
Why Does DB_CHARSET latin1 Help?
Defining WordPress’ DB_CHARSET variable to be latin1 sounds like it’s telling WordPress what type of character set is used by the database. But if you think it through, that doesn’t fit the evidence here. If I tell WordPress that my DB data is in Latin1 format, even though as we’ve seen it’s really UTF-8, then I would expect WordPress to convert the data bytes from Latin1 to UTF-8 as it loads them during a page render. That would do exactly the wrong thing; it would cause the very problem that I’m trying to prevent.
I searched for a detailed explanation of precisely what the DB_CHARSET setting does, but couldn’t find one that made sense to me. Most references just say to change the value, without fully explaining what it does.
While I don’t have any strong evidence to support this, my guess is that a MySQL client has a choice of connecting to the MySQL database in Latin1 mode or UTF-8 mode, and this is what DB_CHARSET controls for WordPress. If the client connects as a UTF-8 client but the table is marked as being Latin1, my guess is MySQL automatically translates the data. Normally that would be a good thing, but if UTF-8 data were stored in a table improperly marked as being Latin1, it would cause unwanted and unnecessary character conversions, causing the types of problems I saw on the blog.
Why Did This Break Now?
So what changed during the recent MySQL update to suddenly break this? Why did the problem appear now? Initially I suspected the underlying data bytes had become corrupted during the update, but the hex display from phpmyadmin showed the data bytes are OK.
I can’t say for certain whether the problem was caused by exporting and reimporting my database, or whether it’s due to new behavior in MySQL 8. Now that I think about it, I’m not even certain whether the result I saw from that show create table wp_comments was actually the original SQL command from 2007, or the SQL command from eight days ago when the database was migrated to MySQL 8.
If these database tables were always explicitly marked Latin1, going all the way back to 2007, then I think this character set conversion problem would always have happened too. Or at least it would have happened as soon as I updated to my current version of WordPress, instead of when I updated to a new version of MySQL.
One possibility is that with the old database and old version of MySQL, the character set for the database tables wasn’t explicitly defined. It relied on some database-wide default which just happened to be UTF-8, so everything worked when WordPress connected to the DB as a UTF-8 client. Then during the MySQL 8 update, somehow the tables were explicitly set to Latin1 and the problem appeared.
Another possibility is that the tables were already explicitly Latin1, but WordPress was previously connecting to the database as a Latin1 client, so it worked OK. Since my version of WordPress hasn’t changed recently, this would mean the default database connection type for WordPress must somehow come from the database itself, or the database server, and that’s what changed during the MySQL 8 update.
Whatever the explanation, changing DB_CHARSET now seems like only a temporary solution. I still have UTF-8 data stored in tables that say they’re Latin1, which seems likely to cause more problems down the road. If nothing else, it makes the output display incorrectly in the phpmyadmin UI. A full solution will probably require some more significant database maintenance, but I hope to postpone that for a while.
Read 3 comments and join the conversationNon-Breaking Spaces and UTF-8 Madness

A few months back I wrote about some web site troubles with the HTML entity, non-breaking spaces, and UTF-8 encoding. A similar problem has reared its head again, but in a surprising new form that seems to have infected previously-good web pages on this site. If you view the Floppy Emu landing page right now, and scroll down to the product listing details, you’ll see a mass of stray  characters everywhere, screwing up the item listings and making the whole page look terrible. Further down the page in the Documentation section, the Japanese hiragana label that’s supposed to accompany the Japanase-language manual appears rendered as a series of accented Latin letters and square boxes.
The direct UTF-8 encoding for a non-breaking space (without using the entity) is C2 80. Â is Unicode character U+00C2, Latin capital letter A with circumflex. So somehow the C2 value is being interpreted as a lone A with circumflex character rather than part of a two-byte sequence for non-breaking space.
The strangest part of all this is that the Floppy Emu landing page hasn’t been modified since September 6, and I’m sure it hasn’t looked this way for the past month. In fact the most recent archive.org snapshot from September 8 shows the page looking fine. So what’s going on?
I’ve noticed a related problem with some other pages on the site. The Mac ROM-inator II landing page hasn’t been modified in six months, but it too shows strange encoding problems. The sixth bullet point in the feature list is supposed to say Happy Mac icon is replaced by a color smiling “pirate” Mac, with the word pirate in curly double-quotes. In the most recent archive.org snapshot it looks correct. But if you view the page today, the curly quotes are rendered as a series of accented letters and Euro currency symbols. There are similar problems elsewhere on that page, for example in the second user comment, Kristian Möller’s name is rendered incorrectly.
These problems are visible in all the different browsers I tried. And none of them seem to correspond to any specific change I made in the content of those pages recently.
I’m not a web developer or HTML expert, but I’m wondering if the header of all my HTML pages somehow got broken, and it’s not correctly telling the web browsers to interpret the data as UTF-8. But when I view the page source using the Chrome developer tools, the fourth line looks right:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
And what’s more, Unicode characters in this very blog post appear to render just fine. For example I can copy-paste those hiragana characters from the archive.org snapshot of the Floppy Emu page, and paste them here without any special encoding tricks, and they render correctly:
??????????????
Nevermind, I’m wrong. I can paste those characters into the WordPress editor, and they appear correctly, but as soon as I save a draft or preview the page they turn into a string of question marks. I’m sure that direct copy-and-paste of this text used to work, it’s how I added this text to the Floppy Emu page in the first place.
So if the character set is configured correctly in my pages’ HTML headers (which I could be wrong about), what else could explain this? The alternative is that the text is stored in a broken form in the WordPress database, or is being broken on-the-fly as the page’s HTML is generated. Perhaps some recent WordPress action or update caused the text of previously-written pages to be parsed by a buggy filter with no UTF-8 awareness and then rewritten to the WordPress DB? But I haven’t changed any WordPress settings recently, performed any upgrades, or installed any new plugins. I can’t explain it.
I dimly recall seeing a notice from my web host (Dreamhost) a few weeks ago, saying they were updating something… I think MySQL was being upgraded to a newer version. Maybe that’s a factor here?
Whatever the cause, the important question is how to fix this mess. I could go manually edit all the affected pages, but that would be tedious, and I wouldn’t really be confident the problem would stay fixed. Even if I were willing to make manual fixes, it still wouldn’t fix everything, since some of the broken text is in users’ names and comment text rather than in my own page text. For the moment, I’m stumped until I can figure this out.
An Example: Möller
On the ROM-inator page there’s a comment from Kristian Möller. I’m using the explicit HTML entity here for o with umlaut to ensure it renders correctly. Until recently, it also looked correct on the ROM-inator page, but now it appears as Möller, again using explicit HTML entities for clarity. So what happened?
The two-byte UTF-8 encoding for ö is 0xC3 0xB6. The one-byte Latin-1 encoding for à is 0xC3 and for ¶ is 0xB6. So a UTF-8 character is being misinterpreted as two Latin-1 characters, but where exactly is it going wrong? Is the browser misinterpreting the data due to a faulty HTML character encoding meta tag? Is the data stored incorrectly in the WordPress DB? Or is WordPress converting the data on the fly when it retrieves it from the DB to generate the page’s HTML? I did a small test which I think eliminates one of these possibilities.
First I wrote a simple Python 2 program to download and save the web page’s HTML as binary data:
import urllib2
contents = urllib2.urlopen('http://www.bigmessowires.com/mac-rom-inator-ii/').read()
open('mac-rom-inator-ii.html', 'wb').write(contents)
I think this code will download the bytes from the web server exactly as-is, without doing any kind of character set translations. If urllib2.urlopen().read() does any character translation internally, then I’m in trouble. Next I examined the downloaded file in a hex editor:
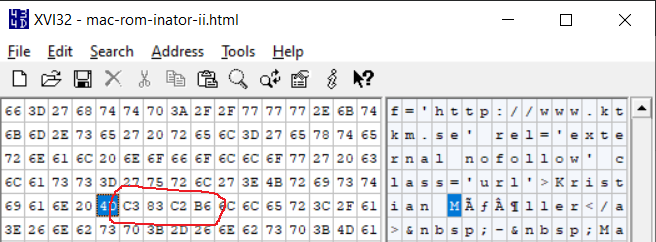
This shows that what the web browser renders as ö is a four-byte sequence 0xC3 0x83 0xC2 0xB6. Those are the two-byte UTF-8 sequences for à and ¶. So this doesn’t look like the web browser’s fault, or a problem with the HTML character encoding meta tag. It looks like the data transmitted by the web server was wrong to begin with, it really is sending à and ¶ instead of ö.
This leaves two possibilities:
- During the MySQL upgrade, 0xC3 0xB6 in the database was misinterpreted as two Latin-1 characters instead of a single UTF-8 character, and was stored UTF-8-ified in the new MySQL DB as 0xC3 0x83 0xC2 0xB6.
- 0xC3 0xB6 was copied to the new MySQL DB correctly, but a DB character encoding preference went wrong somewhere, and now WordPress thinks this is Latin-1 data. So when it retrieves 0xC3 0xB6 from the DB, it converts it to 0xC3 0x83 0xC2 0xB6 in the process of generating the page’s final HTML.
I could probably tell which possibility is correct if I used mysqladmin to dump the relevant DB table as a binary blob and examine it. But I’m not exactly sure how to do that, and I’m a bit fearful I’d accidentally break the DB somehow.
If possibility #1 is correct, then the DB data is corrupted. There’s not much I could do except restore from a backup, or maybe look for a tool that can reverse the accidental character set conversion, assuming that’s possible.
If possibility #2 is correct, then I might be able to fix this simply by changing the faulty encoding preference. I need to find how to tell WordPress this is UTF-8 data, not Latin-1, so just use it as-is and don’t try to convert it.
Read 8 comments and join the conversation