

Archive for the 'Bit Bucket' Category
Discovery Day!

Every year I lead a group of kids in the construction of an “Electric Scribbling Machine”, as part of the local elementary school’s Discovery Day program. The program sessions are run by parents and local community members, and can be anything from karate to marshmallow cannons to frog dissection. The kids range in age from 7 to 10 years, and the sessions are only 50 minutes long, so it’s a challenge to design interesting projects to fit the available time and skill level of the kids. Despite the challenges, we always manage to have lots of fun!
The scribbling machine concept is simple:
- Attach an off-center weight to an electric motor, so it wobbles and vibrates
- Attach the motor to some kind of body
- Attach colored markers to the body as “legs”
- Set the machine on a large sheet of paper, and watch it go!
I use cheap DC hobby motors rated for 1.5V to 6.0V, with an AA battery. The off-center weight is a glue stick (designed for a hot glue gun), with a small pre-cut hole that press-fits onto the motor shaft. The body is an empty plastic water bottle, and the legs are washable Crayola markers. What could go wrong?
If you guessed there would be tons of problems, you’re right. In past years, we used rubber bands to hold the battery and legs to the body, and the motor wires to the battery. Kids and rubber bands don’t mix well in this project – most of them lack the physical dexterity needed to twist a rubber band around two objects and hold them in place. They struggle with it, accidentally crush the water bottle, and get frustrated. Rubber bands on the battery for the motor wires are also a problem. You can imagine how unreliable that connection can be, and there’s no easy on/off switch.
A New Design for 2016
This year we made two big changes to the design. I bought a pile of 2xAA battery holders with an integrated on/off switch, for a much simpler and frustration-free electrical connection. And I replaced all the rubber bands with duct tape. Who doesn’t love duct tape? With these changes, we were guaranteed a problem-free Discovery Day, right?
The battery holders were a clear improvement, and I was pleased with how they worked out. The duct tape was a mixed bag. It was certainly easier for the kids, and it allowed the legs to be attached in more orientations than are possible with rubber bands. But if you’re not the parent of an 8-year-old, it may be hard to appreciate just how big of a mess kids can make with tape. There were wads of snarled tape everywhere, and when someone wanted to un-tape a leg and make an adjustment, it was difficult.


I could live with snarled tape, but the bigger issue came from an unexpected source: the solder connections. Of 24 battery and motor packs, we had at least 12 that failed in various ways. Sometimes the wire broke off at the motor, and sometimes at the battery pack. This was a surprise, since we used the same motors soldered in the same way as previous years, where I’d only ever experienced one or two breaks before. During the first session, we went through all of the packs for that session and half of the packs intended for the second session. I raced home to get my soldering iron during the short break between sessions, and repaired as many packs as I could. In the end we had enough for everyone, but the fragility of the packs was surprising and frustrating for the kids.
After the scribbling machines were more-or-less finished, it was great to see some of the kids experimenting with different designs. Longer or shorter legs, angled or straight, flat-footed or precariously balanced… each produced a different kind of motion in the resulting machine. Some spun in lazy circles, while others raced straight ahead like a car. All of them made interesting spiral and dot patterns on the paper as they went.
I believe I used the words “magnetic field” at least once during the session, so that counts as educational. Success!

AV2HDMI Video Adapter for Apple II

Many retro computers and game systems have a composite video output – the familiar round yellow plug. Unfortunately, composite video inputs are increasingly rare on modern TVs and computer monitors, creating a headache for retro enthusiasts. This is a mini-review of one solution to this problem: a composite video (and stereo audio) to HDMI converter box called AV2HDMI, which I purchased for $18 from Amazon.com.
Converting composite video to a more modern format is more difficult than it might first appear. It’s not merely a matter of physically converting one plug shape to another. Composite video is an analog signal that combines the color, luminance, and frame synchronization information all on the same wire. It comes in different formats like NTSC, PAL, and SECAM, which imply a different number of horizontal lines per frame and frames per second. The signal is also interlaced, meaning that the even lines are sent in one frame and the odd lines in the next frame.
A converter must detect the input format correctly, separate the color/luminance/sync info, deinterlace the lines, perform analog-to-digital conversion, upscale the resolution, and output a more modern VGA or DVI or HDMI signal. There are plenty of opportunities for things to go wrong and generate a poor quality result. It doesn’t help matters when the original composite video signal doesn’t quite meet the NTSC spec in the first place, as is the case for the Apple II series.
AV2HDMI
The AV2HDMI box that I purchased is one of at least 20 very similar items on Amazon, all with the identical case and connectors, but with different names, colors, and labels. It seems likely that these are all really the same device, with the guts manufactured by a single vendor, and then many other vendors packaging and rebranding it. The case is sealed tight, without any screws or other obvious methods of disassembly, so I couldn’t peek inside to learn more.
Previously I was using the composite video input on a Dell 2001FP LCD monitor, which seems to be known for good handling of composite video. But in an effort to declutter my desk, I really wanted to get my Apple II systems working with the primary Asus monitor that I also use for my PC and Macintosh work. Keeping around the Dell 2001FP just for occasional use was a hassle, so my main motivation in purchasing this converter was convenience rather than top-quality video output. I also wanted something that could work with any Apple II system, as well as old video game systems, rather than a solution that’s specific to any one model of Apple II.
The overall results from the AV2HDMI aren’t quite as good as the 2001FP, but they’re close, so I’m happy. I can’t decide if it’s stretching the 4:3 image to 16:9 or not – it seems maybe half stretched, like something midway between the two aspect ratios. It didn’t bother me. The output has very good contrast and color saturation. It’s also quite sharp, which isn’t necessarily a good thing. The 2001FP produces slightly fuzzier-looking output, which I think is more faithful to the appearance of an old-shool CRT, and helps make certain color-fringing artifacts less objectionable, but the difference is minor.
The AV2HDMI appears to have some kind of auto-configuring behavior, where it adjusts itself to the incoming video signal’s format, black levels, etc. This takes about two seconds, during which the image isn’t visible. Switching video modes on the Apple II (say between text and low-res graphics mode) forces a repeat of the auto-configure logic, so there’s a few seconds of black screen when switching modes. It’s a little bit annoying, but not too bad.
Testing
All of these tests but one were performed on an Apple IIgs. Pure text modes looked good in 40 and 80 columns, as did color games. The higher resolution GSOS desktop was acceptable in black and white, but suffered from minor shimmering and sparkle. GSOS in color was pretty bad, but remember this is still composite video, and GSOS never really looked very good on a composite monitor.
In the pure text modes, the computer disables the NTSC colorburst, which makes the monitor think it has a purely black and white video signal. This helps a lot, and results in a nice crisp image with the AV2HDMI. In low-res graphics mixed mode, with four lines of text at the bottom of the screen, the colorburst is enabled and the text looks markedly worse. Substantial amounts of green/purple fringing are visible on the edges of each text character. The 2001FP does a little bit better in this case, but still shows the same kinds of artifacts. I recall seeing those same green/purple artifacts back in the day, so I know they’re real and not due to some problem with the video conversion. I don’t recall them having been quite so dramatic as they appear now, but it’s been a long time.
AV2HDMI Photos

AV2HDMI color game
AV2HDMI pure text mode (80 column)
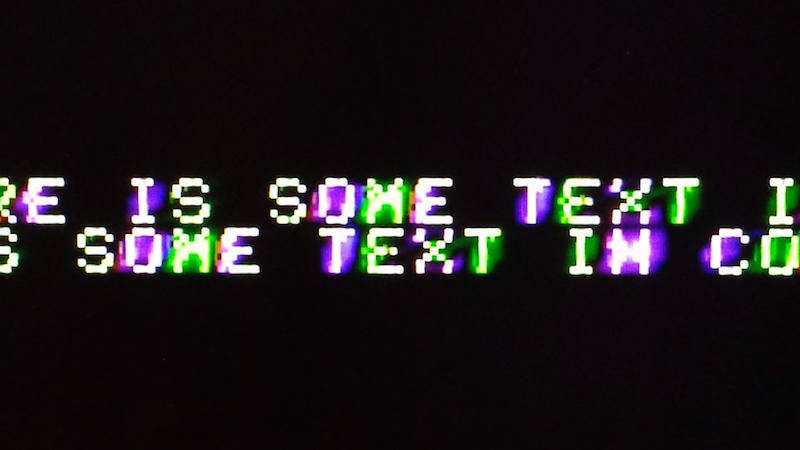
AV2HDMI mixed mode text close-up

AV2HDMI mixed mode text on Apple IIc
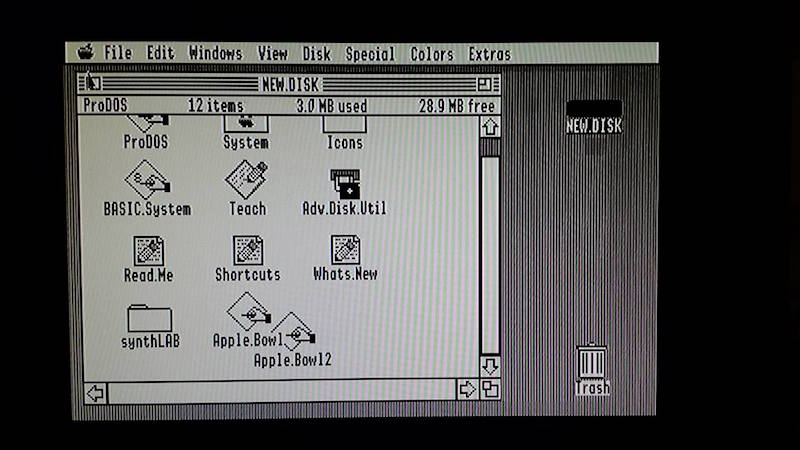
AV2HDMI GSOS desktop, monochrome mode
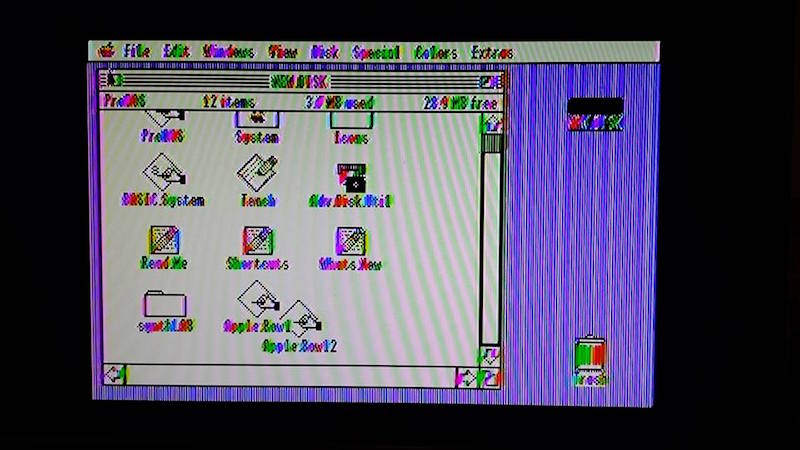
AV2HDMI GSOS desktop, color mode
Dell 2001FP Comparison Photos

2001FP color game
2001FP mixed mode text close-up
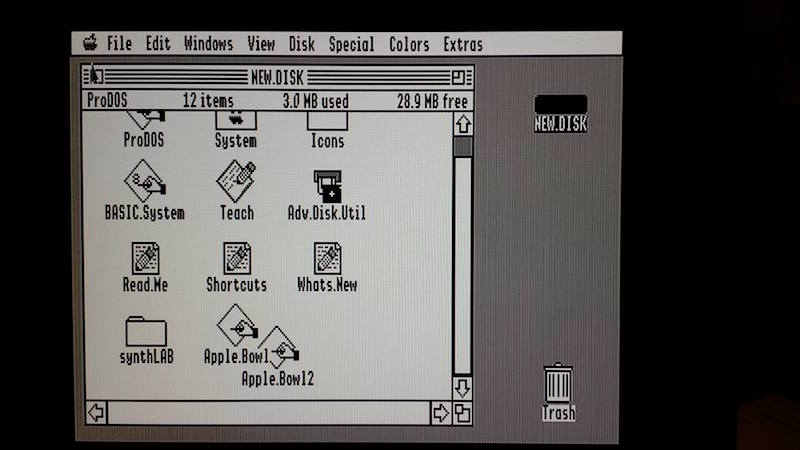
2001FP GSOS desktop, monochrome mode
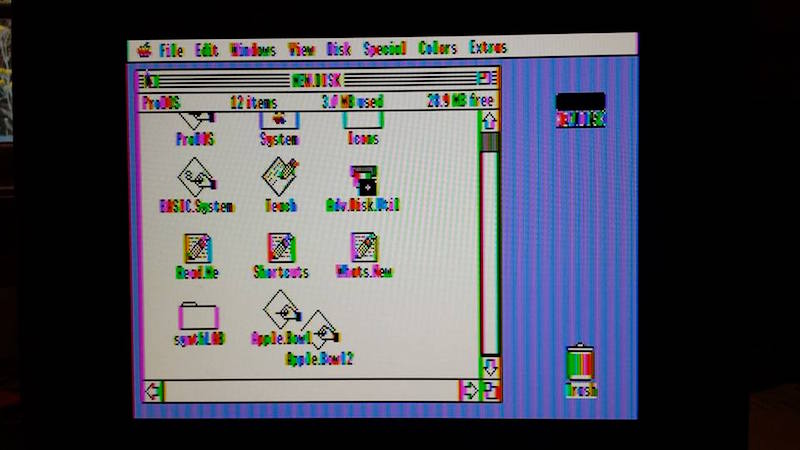
2001FP GSOS desktop, color mode
For the money, I think the AV2HDMI is a good solution for semi-frequent use. The Dell 2001FP was slightly better overall, and a real composite CRT would surely have been better still (I don’t have one). There are also machine-specific VGA adapters available for some Apple II systems. But because I don’t boot my Apple II hardware very often, this was exactly what I needed to simplify my set-up.
Read 7 comments and join the conversationThe Amiga Years

I recently watched a new documentary about the Amiga years: From Bedrooms to Billions. It’s a $5 Vimeo rental that will be fascinating for anyone who lived through the 1980’s home computer revolution, or who’s interested in retro-computing technology. I was pleased to see a fair amount of technical content, as well as tons of interviews and more general discussion of the Amiga “scene” and the contemporary computer industry. There’s some nice discussion of other period computer systems too, especially the Atari ST series.
Amiga was a Silicon Valley start-up company, founded by Jay Miner and staffed by many ex-Atari engineers. They ran into financial difficulties during development, and were eventually bought by Commodore. The first Commodore Amiga 1000 computer was released in 1985, and its graphics, sound, and multitasking capabilities were far beyond any other home computer of the time, except perhaps for the Atari ST. As a high school student, I bought a second-hand Amiga 1000 system in 1989 and was absolutely stunned by its graphics fidelity. Yet I never really got into programming or hacking with the Amiga, and in my life it functioned only as a fancy game machine. I switched to a Macintosh when I went to university, and never looked back.
The Amiga Years reminds me of a few other nice documentaries about early computer history.
Get Lamp – A two-hour look into text adventure games, their roots in spelunking and Dungeons and Dragons, and especially Colossal Cave Adventure and Infocom. You are likely to be eaten by a grue.
BBS: The Documentary – Before the internet was common for home users, there were modems and bulletin board systems. This documentary does a great job of describing the BBS scene, as well as some of the technical backstory surrounding protocols and software that I’d never heard before.
What tech documentaries have you seen and enjoyed?
Read 2 comments and join the conversationFC8 – Faster 68K Decompression

Data compression is fun! I’ve written a new compression scheme that’s designed to be as fast as possible to decompress on a 68K CPU, while still maintaining a decent compression density. I’m calling it FC8, and you can get the generic C implementation and optimized 68K decompressor from the project’s Github repository. I’ve probably reinvented the wheel with this, and in a non-optimal way too, but once I started I found that I couldn’t stop. My intended platform for FC8 is 68020 and 68030-based vintage Macintosh computers, but it should be easily portable to other classic computers, microcontrollers, and similar minimal systems.
The main loop of the 68K decompressor is exactly 256 bytes, so it fits entirely within the instruction cache of the 68020/030. Decompression speed on a 68030 is about 25% as fast as an optimized memcpy of uncompressed data, which is essentially an unrolled loop of 4-byte move.l instructions with no computation involved. Compared to that, I think 25% is pretty good, but I can always hope for more. 🙂
In the previous post, I described how I was using compression to squeeze a larger rom-disk image into a custom replacement Macintosh ROM that I’m designing. I began with a compression algorithm called LZG, written by Marcus Geelnard. It worked well, but the 68K decompression seemed disappointingly slow. I tried to contact the author to discuss it, but couldn’t find any email address or other contact info, so I eventually drifted towards creating my own compression method loosely based on LZG. This became FC8. On a 68030 CPU, FC8 compresses data equally as tightly as LZG and decompresses 1.5x to 2x faster. FC8 retains much of the compression acceleration code from LZG, as well as the idea of quantizing lengths, but the encoding and decompressor are new.
The algorithm is based on the classic LZ77 compression scheme, with a 128K sliding history window and with duplicated data replaced by (distance,length) backref markers pointing to previous instances of the same data. No extra RAM is required during decompression, aside from the input and output buffers. The compressed data is a series of tokens in this format:
- LIT = 00aaaaaa = next aaaaaa+1 bytes are literals
- BR0 = 01baaaaa = backref to offset aaaaa, length b+3
- EOF = 01×00000 = end of file
- BR1 = 10bbbaaa’aaaaaaaa = backref to offset aaa’aaaaaaaa, length bbb+3
- BR2 = 11bbbbba’aaaaaaaa’aaaaaaaa = backref to offset a’aaaaaaaa’aaaaaaaa, length lookup_table[bbbbb]
The encoding may look slightly strange, such as only a single bit for the backref length in BR0, but this produced the best results in my testing with sample data. The length lookup table enables encoding of backrefs up to 256 bytes in length using only 5 bits, though some longer lengths can’t be encoded directly. These are encoded as two successive backrefs, each with a smaller length.
The biggest conceptual changes vs LZG were the introductions of the LIT and EOF tokens. EOF eliminates the need to check the input pointer after decoding each token to determine if decompression is complete, and speeds things up slightly. LIT enables a whole block of literals to be quickly copied to the output buffer, instead of checking each one to see if it’s a backref token. This speeds things up substantially, but also swells the size of the data. In the worst case, a single literal would encode as 1 byte in LZG but 2 bytes in FC8, making it twice as expensive! All the other changes were needed to cancel out the compression bloat introduced by the LIT token, with the end result that FC8 compresses equally as compactly as LZG. Both compressed my sample data to about 63% of original size.
The 68K decompressor code can be viewed here.
Decompression on the Fly
Several people mentioned the possibility of on-the-fly decompression, since the intended use is a compressed disk image. That’s something I plan to explore, but it’s not as simple as it might seem at first. Disk sectors are 512 bytes, but there’s no way to decompress a specific 512 byte range from the compressed data, since the whole compression scheme depends on having 128K of prior data to draw on for backref matches. You could compress the entire disk image as a series of separate 512 byte blocks, but then the compression density would go to hell. A better solution would compress the entire disk image as a series of larger blocks, maybe 128K or a little smaller, and then design a caching scheme to keep track of whether the block containing a particular sector were already decompressed and available. This would still have a negative impact on the compression density, and it would make disk I/O slower, but would probably still be OK.
Ultimately I think the two decompression approaches each have strengths and weaknesses, so the best choice depends on the requirements.
Boot-Time Decompression:
Pros: Best compression density, fastest I/O speeds once the disk image is decompressed
Cons: 5-10 second wait for decompression at boot time, requires enough RAM to hold the entire disk image
On-the-Fly Decompression:
Pros: No wait at boot time, required amount of RAM is configurable (size of the decompressed block cache)
Cons: Worse compression density, slower I/O speeds, more complex implementation
Hardware Tests
I discovered that a Macintosh IIci in 8-bit color mode decompresses about 20% slower than in 1-bit color mode. But a IIsi decompresses at the same speed regardless of the color settings. Both machines are using the built-in graphics hardware, which steals some memory cycles from the CPU in order to refresh the display. I’m not sure why only the IIci showed a dependence on the color depth. Both machines should be faster when using a discrete graphics card, though I didn’t test this.
The original LZG compression showed a much bigger speed difference between the IIci and IIsi, closer to a 50% difference, which I assumed was due to the 32K cache card in the IIci as well as its faster CPU. It’s not clear why the discrepancy is smaller with FC8, or whether it means the IIci has gotten worse or the IIsi has gotten better, relatively speaking. Compared to the same machine with the LZG compression, FC8 is 1.57x faster on the IIci and 1.99x faster on the IIsi. Based on tests under emulation with MESS, I was expecting a 1.78x speedup.
Tradeoffs
While working on this, I discovered many places where compression compactness could be traded for decompression speed. My first attempt at FC8 had a minimum match size of 2 bytes instead of 3, which compressed about 0.7% smaller but was 13% slower to decompress due to the larger number of backrefs. At the other extreme, the introduction of a LIT token without any other changes resulted in the fastest decompression speed of all, about 7% faster than FC8, but the compressed files were about 6% larger, and I decided the tradeoff wasn’t worth it.
I explored many other ideas to improve the compression density, but everything I thought of proved to have only a tiny benefit at best, not enough to justify the impact on decompression speed. An algorithm based on something other than LZ77 would likely have compressed substantially more densely, or say a combination of LZ77 and Huffman coding. But decompression of LZ77-based methods are far easier and faster to implement.
Compression Heuristics
It eventually became obvious to me that defining the token format doesn’t tell you much about how to best encode the data in that format. A greedy algorithm seemed to work fairly well, so that’s what I used. At each point in the uncompressed data, the compressor substitutes the best match it can make (if any) between that data and previous data in the history window.
However, there are some examples where choosing a non-optimal match would allow for an even better match later, resulting in better overall compression. This can happen due to quirks in the quantizing of match lengths, or with long runs of repeated bytes which are only partially matched in the previous data. It’s a bit like sacrificing your queen in chess, and sometimes you need to accept a short-term penalty in order to realize a long-term benefit. Better compression heuristics that took this into account could probably squeeze another 1% out of the data, without changing the compression format or the decompressor at all.
Read 11 comments and join the conversationOptimizing Assembly (Fast 68K Decompression)

Are you a 68K assembly language guru, or just good at optimizing code? I’m working on a project that’s a replacement ROM for old 68K-based Macintosh computers, part of which involves decompressing a ~5MB disk image from ROM into RAM to boot the machine. This needs to happen fast, to avoid a lengthy wait whenever the computer boots up. I selected liblzg specifically for its simplicity and speed of decompression, even though it doesn’t compress as well as some alternatives. And the whole thing works! But I want it to be faster.
The compressor is a regular Windows/Mac/Linux program, and the decompressor is a hand-written 680000 assembly routine from the lzg authors. It works well, but decompression on a Mac IIsi or IIci only runs about 600K/sec of decompressed data, so it takes around 5-20 seconds to decompress the whole rom disk depending on its size and the Mac’s CPU speed.
The meat of the 68000 decompression routine isn’t too long. It’s a fairly simple Lempel-Ziv algorithm that encodes repeated data as (distance,length) references to the first appearance of the data. There’s a brief summary of lzg’s specific algorithm here. Anyone see any obvious ways to substantially optimize this code? It was written for a vanilla 68000, but for this Mac ROM it’ll always be running on a 68020 or ‘030. Maybe there are some ‘030-specific instructions that could be used to help speed it up? Or some kind of cache prefetch? There’s also some bounds-checking code that could be removed, though the liblzg web site says this provides only a ~12% improvement.
The meat-of-the-meat where data gets copied from source to dest is a two-instruction dbf loop:
_loop1: move.b (a4)+,(a1)+ dbf d6,_loop1
If any ‘030-specific tricks could improve that, it would help the most. One improvement would be to copy 4 bytes at a time with move.l instead of move.b. But the additional instructions needed to handle 4-byte alignment and 1-3 extra bytes might outweigh the savings for smaller blocks being copied. I think the average block size is around 10 bytes, though some are up to 127 bytes.
The loop might also be unrolled, for certain pre-defined block sizes.
Here’s the entirety of the decompressor’s main loop:
_LZG_LENGTH_DECODE_LUT: dc.b 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16 dc.b 17,18,19,20,21,22,23,24,25,26,27,28,34,47,71,127 _lzg_decompress: // a0 = src // a1 = dst // a2 = inEnd = in + inSize // a3 = outEnd = out + decodedSize // a6 = out move.b (a0)+,d1 // d1 = marker1 move.b (a0)+,d2 // d2 = marker2 move.b (a0)+,d3 // d3 = marker3 move.b (a0)+,d4 // d4 = marker4 lea _LZG_LENGTH_DECODE_LUT(pc),a5 // a5 = _LZG_LENGTH_DECODE_LUT // Main decompression loop move.l #2056,d0 // Keep the constant 2056 in d0 (for marker1) cmp.l a2,a0 _mainloop: bcc.s _fail // Note: cmp.l a2,a0 must be performed prior to this! move.b (a0)+,d7 // d7 = symbol cmp.b d1,d7 // marker1? beq.s _marker1 cmp.b d2,d7 // marker2? beq.s _marker2 cmp.b d3,d7 // marker3? beq.s _marker3 cmp.b d4,d7 // marker4? beq.s _marker4 _literal: cmp.l a3,a1 bcc.s _fail move.b d7,(a1)+ cmp.l a2,a0 bcs.s _mainloop // We're done _done: // irrelevant code removed bra _exit // marker4 - "Near copy (incl. RLE)" _marker4: cmp.l a2,a0 bcc.s _fail moveq #0,d5 move.b (a0)+,d5 beq.s _literal // Single occurance of the marker symbol (rare) move.l d5,d6 and.b #0x1f,d6 move.b (a5,d6.w),d6 // length-1 = _LZG_LENGTH_DECODE_LUT[b & 0x1f] lsr.b #5,d5 addq.w #1,d5 // offset = (b >> 5) + 1 bra.s _copy // marker3 - "Short copy" _marker3: cmp.l a2,a0 bcc.s _fail moveq #0,d5 move.b (a0)+,d5 beq.s _literal // Single occurance of the marker symbol (rare) move.l d5,d6 lsr.b #6,d6 addq.w #2,d6 // length-1 = (b >> 6) + 2 and.b #0x3f,d5 addq.w #8,d5 // offset = (b & 0x3f) + 8 bra.s _copy // marker2 - "Medium copy" _marker2: cmp.l a2,a0 bcc.s _fail moveq #0,d5 move.b (a0)+,d5 beq.s _literal // Single occurance of the marker symbol (rare) cmp.l a2,a0 bcc.s _fail move.l d5,d6 and.b #0x1f,d6 move.b (a5,d6.w),d6 // length-1 = _LZG_LENGTH_DECODE_LUT[b & 0x1f] lsl.w #3,d5 move.b (a0)+,d5 addq.w #8,d5 // offset = (((b & 0xe0) << 3) | b2) + 8 bra.s _copy // marker1 - "Distant copy" _marker1: cmp.l a2,a0 bcc.s _fail moveq #0,d5 move.b (a0)+,d5 beq.s _literal // Single occurance of the marker symbol (rare) lea 1(a0),a4 cmp.l a2,a4 bcc.s _fail move.l d5,d6 and.b #0x1f,d6 move.b (a5,d6.w),d6 // length-1 = _LZG_LENGTH_DECODE_LUT[b & 0x1f] lsr.w #5,d5 swap d5 move.b (a0)+,d5 lsl.w #8,d5 move.b (a0)+,d5 add.l d0,d5 // offset = (((b & 0xe0) << 11) | (b2 << 8) | (*src++)) + 2056 // Copy corresponding data from history window // d5 = offset // d6 = length-1 _copy: lea (a1,d6.l),a4 cmp.l a3,a4 bcc _fail move.l a1,a4 sub.l d5,a4 cmp.l a6,a4 bcs _fail _loop1: move.b (a4)+,(a1)+ dbf d6,_loop1 cmp.l a2,a0 bcs _mainloop bra _done
Another thing to note is that about half of all the data is literals rather than (distance,length) markers, and goes to the _literal branch above. That involves an awful lot of instructions to copy a single byte. A faster method of determining whether a byte is a marker or a literal would help - I plan to try a 256-entry lookup table instead of the four compare and branch instructions.
My final idea would involve changing the lzg algorithm itself, and making the compression slightly worse. For longish sequences of literals, the decompressor just copies bytes from input to output, but it goes through the whole _literal loop for each byte. I'm thinking of introducing a 5th marker byte that means "copy the next N bytes directly to output", for some hand-tuned value of N. Then those N bytes could be copied using a much higher performance loop.
Read 35 comments and join the conversationCapacitor Replacement in a Vintage Power Supply

Capacitors don’t last forever – an unfortunate fact of life for those who collect vintage electronics. The common electrolytic capacitor is one of the most problematic. It’s the type that looks like a little metal can, and after a couple of decades electrolytics tend to start leaking corrosive capacitor goo onto the PCB. You may recognize the strange smell of fish as an early warning sign. Eventually the goo will destroy traces on the PCB, or the changing electrical properties of the capacitor will cause the circuit to stop working. If you want to preserve your vintage equipment, that’s when it’s time for a “recap”.
I have an old Macintosh IIsi computer that dates from around 1991. A few years ago it started acting funny and having trouble turning on, so I sent the logic board to Charles Phillips’ MacCaps Repair Service. He did a great job with the capacitor replacement, and the machine was working great again. But then a few months ago it started to develop new problems that pointed to the need for a power supply recap. I could rarely get it to turn on at all, and when it did, I couldn’t get it to turn off again without unplugging it. Simply plugging the computer into wall power without turning it on caused strange clicking noises from the PSU. And oh, that fish smell.
I was going to send the PSU off for a recap. After all, there’s a big warning printed right on the metal cover saying danger, do not open, no user-serviceable parts inside. And while there’s not much danger in a 5 volt logic board, there is a potential for real danger in a power supply drawing 5 amps at 110 volts AC. But then I thought no, I should really get comfortable doing this kind of work myself. I have the tools and the skills, just not the experience or confidence. What’s the worst that could happen? OK, it could blow up and catch fire, but I’ve got a fire extinguisher. 🙂

There are 12 electrolytic capacitors in this power supply, whose types and values are listed here. Two of these are surface mount caps on a daughterboard that’s connected to the main PCB, and the others are all through-hole caps. Because I’m both timid and lazy, I really did not want to replace 12 caps. After reading this discussion thread from someone who did a similar repair, I decided to replace only the three capacitors that seemed most likely to be causing the problem. Two of these were the SMD caps on the daughterboard, which apparently are involved in some kind of PWM control circuit. The third was a 400V cap in the AC section of the power supply. It’s located directly next to some big heat sink thing, and has probably been slowly baking for 25 years.
To help with the job, I bought a cheapo vacuum desoldering iron. This makes desoldering of through-hole components easy. Just put the iron over the pin, hold for a second, then press the button to release the plunger and mostly all the solder is sucked up. I used this to desolder the daughterboard too. I had to revisit a few pins to get them totally clean, but overall the process was simple. I don’t do enough desoldering to justify the cost of a fancier desoldering gun with a continuous suction vacuum pump, so this seemed like a good tool for occasional use.

I removed the two SMD capacitors on the daughterboard with a hot air tool. I’m not sure how you would do that without such a tool – just rip them off with pliers? The hot air worked fine, except when I used tweezers to slide off the caps after the solder had melted, I accidentally pushed one of them right through a bunch of other little SMD components, whose solder had also melted, and ended up with a jumbled heap of little components half soldered together in a corner of the board. Ack!!
Here’s the daughterboard, before I wrecked it. The four components at bottom right were all pushed into a pile in the corner. A couple of them actually fell off the board, as did one of the pins. But with some patience I was able to separate them all and get things cleaned up, and I think I even put everything back where it was originally. 🙂 After removing the old caps, I cleaned up the board with isopropyl alcohol and a toothbrush to remove the capacitor goo.

The last step was soldering in new capacitors, and putting it all back together. Compared to everything else, that was a breeze.
When the time came for testing, I didn’t take any chances. I brought the whole machine outside, with a fire extinguisher in hand, ready for anything! I plugged it in, pressed the power switch, and… WOOHOO! It booted right up, and everything now looks a-ok. I can boot from the rear power switch or the keyboard power button, and the soft power-off function works again too. I feel like Superman!
This was my first time recapping anything, and I won’t be so timid about recapping next time the need arises. The whole process took about three hours, including lots of futzing around during disassembly and reassembly. If I hadn’t blundered by knocking off a bunch of unrelated SMD parts, I probably could have done the whole job in about an hour.
Read 18 comments and join the conversation