

When A Space Is Not A Space
I just spent more than two hours troubleshooting a seemingly simple HTML problem. When I copied and pasted a small section of HTML, the web browser displayed the newly-pasted section differently from the original. The horizontal spacing between some of the elements was slightly different, causing the whole page to look wrong. But how could this be? The two HTML sections were identical – the new one was literally a copy of the old one.
This simple-sounding problem defied all my attempts to explain it. I came up with lots of great theories: problems with my CSS classes, or with margins and padding. Mismatched HTML tags. Browser bugs. I tried three different browsers and got the same results in all of them.
Feeling very confused, I looked again at the two sections of HTML in the WordPress editor (text view), and confirmed they were exactly identical. Then I tried Firefox’s built-in web developer tools to view the page’s rendered elements, and compared all their CSS properties. Identical – yet somehow they rendered differently. I used the developer tools to examine the exact HTML received from my web server, checked the two sections again, and verified they were character-for-character identical. Firefox’s “page source” tool also confirmed the two sections were exactly identical.
By this point I was getting ready to blame cosmic rays or voodoo magic. I discovered that any time I copy-pasted any similar HTML section, the newly-pasted section would appear in the browser with the wrong element spacing. How could this possibly be? I then tried the W3C Validator, which found some other problems with my page, but nothing that could explain this behavior. And once again, it confirmed that despite rendering differently in the browser, the two sections of HTML were identical.
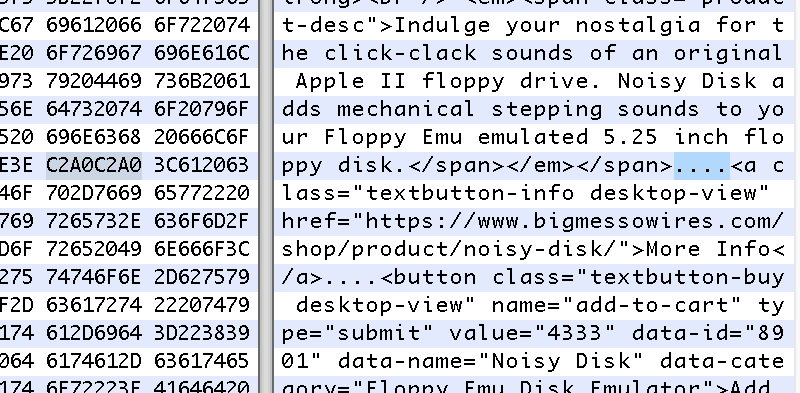
Clearly something wasn’t adding up. I used curl to download the web page from my web server, viewed the local copy, and saw the same behavior as before. But when I opened the stored .html document with a hex editor, I finally had my answer. The two sections of HTML were not identical: one section used a different type of space character from the other.
What the hell.
I discovered that the original HTML section contained non-breaking spaces. But instead of encoding them with the entity, they were encoded directly as Unicode character C2A0. I’m not sure when or how this happened, but I blame WordPress. When viewing this section in the WordPress HTML editor, the C2A0 spaces appeared like normal spaces, and copy-pasting the section inside the editor silently converted non-breaking spaces to normal spaces with hex value 20. So the copied version rendered differently, even though the source HTML appeared to be the same.
This is like the 21st century version of confusing a zero with a capital letter O, yet worse. I wasn’t even aware that non-breaking spaces have a Unicode character value – I thought was the only way to encode them. I changed the HTML back to use and now it all works fine.
I’m surprised at how many different tools failed to reveal this subtle but important difference between types of spaces in the HTML source. The WordPress HTML editor failed to show or correctly handle the difference. The Firefox web developer tools and page source tools failed. The W3C Validator’s source view failed. Curl plus a hex editor was the only way to finally establish the ground truth about the precise contents of the HTML source.
Read 9 comments and join the conversation9 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
Non-breaking space characters are a pain. On Mac, Option + Space makes one of those, which I’m sure makes sense to some professions, but it’s an absolute pain for programmers. I’ve resorted to configuring Vim to highlighting those characters so I can spot them before I run into incomprehensible errors.
At least on classic Macintosh, the character created by Option+Space is non-breaking, and in most fonts doesn’t contain any “ink”, but it isn’t an ordinary non-breaking space. Instead, it is a space whose width should match that of digits 0-9, at least in fonts where those characters all have the same width as each other.
A problem with Unicode editing in general is that there’s no specified canonical way of representing a string in such a fashion as to make it visually distinguishable from any other. Non-breaking spaces are hardly the biggest problem here. Strings like “a.11b” are specified as appearing visually indistinguishable even though the sequence of characters in the second one is “a.X.2>1b” [but with X substituting for the Hebrew alef character]. Fun, eh?
Ouch! 🙂 We’ve all been there. I use BBEdit=>Zap Gremlins to look for problems like this.
Maybe my problem is using the WordPress editor in the first place. But I’m not sure there’s any simple way to use an external editor with WordPress.
Non-breaking space seems like an especially strange example, moreso than things like Hebrew alef, because its difference from a normal space isn’t its appearance but its line-break behavior. I could argue that’s not a proper use of fonts and character sets – it’s more akin to things like specifying boldface and italics, different font sizes, margin widths, indenting, and similar stuff. I think it would make more sense to have an HTML tag or CSS property for spans where spaces shouldn’t be broken, instead of having a special non-breaking space character.
I had a similar problem plaguing the copy-to-clipboard functionality of my coding website. Most browsers inserted non-breaking space characters on empty lines and which made a mess of the code when pasting it into an IDE. I had to use some Javascript to filter them out.
The nominal purpose of Unicode was to provide code for things that already existed in character sets. Many character sets had a character which did not contain any “ink”, but would be treated semantically as a non-space character. While this distinction was most conspicuously important for layout, it had other implications as well. Among other things, if one had a font which placed characters in front of a background (e.g. a “waving banner” font), a space character would often cause the banners on either side to appear with a blank space between them, without the font itself having any say in the matter beyond specifying the width of the space, while a non-breaking space character would be shown as an empty segment of banner that could connect to characters on either side.
In my experience with the same problem, even Sublime Text Editor messes up my HTML whenever I copy-paste something from Microsoft Word to Sublime Text editor. I didn’t realize this issue until my boss had viewed a newsletter email with these non breaking spaces inside of her Gmail account and they displayed a strange block character in their place (I use a mac and she uses windows). Honestly all text editors in 2021 should have a catch where when you paste something with non breaking characters that it alerts you of the conflicts… or something like the (p) paragraph function that displays extra dots for spaces and maybe some red squares for these nbsp. It’s actually giving me motivation to make a wordpress plugin for exactly this scenario.
I’ve also experienced this issue with URL inside a YouTube description… the links appear fine, but when you visit the links, it has these extra characters at the end of the url, causing a 404 page…. and sometimes it comes back when you re-use a video description when you want to go on YouTube Live without changing the description of a previous live video.
Minimizers and optimizers (webpack/…) replace with it’s unicode since it’s a few bytes shorter.