

Non-Breaking Spaces and UTF-8 Madness

A few months back I wrote about some web site troubles with the HTML entity, non-breaking spaces, and UTF-8 encoding. A similar problem has reared its head again, but in a surprising new form that seems to have infected previously-good web pages on this site. If you view the Floppy Emu landing page right now, and scroll down to the product listing details, you’ll see a mass of stray  characters everywhere, screwing up the item listings and making the whole page look terrible. Further down the page in the Documentation section, the Japanese hiragana label that’s supposed to accompany the Japanase-language manual appears rendered as a series of accented Latin letters and square boxes.
The direct UTF-8 encoding for a non-breaking space (without using the entity) is C2 80. Â is Unicode character U+00C2, Latin capital letter A with circumflex. So somehow the C2 value is being interpreted as a lone A with circumflex character rather than part of a two-byte sequence for non-breaking space.
The strangest part of all this is that the Floppy Emu landing page hasn’t been modified since September 6, and I’m sure it hasn’t looked this way for the past month. In fact the most recent archive.org snapshot from September 8 shows the page looking fine. So what’s going on?
I’ve noticed a related problem with some other pages on the site. The Mac ROM-inator II landing page hasn’t been modified in six months, but it too shows strange encoding problems. The sixth bullet point in the feature list is supposed to say Happy Mac icon is replaced by a color smiling “pirate” Mac, with the word pirate in curly double-quotes. In the most recent archive.org snapshot it looks correct. But if you view the page today, the curly quotes are rendered as a series of accented letters and Euro currency symbols. There are similar problems elsewhere on that page, for example in the second user comment, Kristian Möller’s name is rendered incorrectly.
These problems are visible in all the different browsers I tried. And none of them seem to correspond to any specific change I made in the content of those pages recently.
I’m not a web developer or HTML expert, but I’m wondering if the header of all my HTML pages somehow got broken, and it’s not correctly telling the web browsers to interpret the data as UTF-8. But when I view the page source using the Chrome developer tools, the fourth line looks right:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
And what’s more, Unicode characters in this very blog post appear to render just fine. For example I can copy-paste those hiragana characters from the archive.org snapshot of the Floppy Emu page, and paste them here without any special encoding tricks, and they render correctly:
??????????????
Nevermind, I’m wrong. I can paste those characters into the WordPress editor, and they appear correctly, but as soon as I save a draft or preview the page they turn into a string of question marks. I’m sure that direct copy-and-paste of this text used to work, it’s how I added this text to the Floppy Emu page in the first place.
So if the character set is configured correctly in my pages’ HTML headers (which I could be wrong about), what else could explain this? The alternative is that the text is stored in a broken form in the WordPress database, or is being broken on-the-fly as the page’s HTML is generated. Perhaps some recent WordPress action or update caused the text of previously-written pages to be parsed by a buggy filter with no UTF-8 awareness and then rewritten to the WordPress DB? But I haven’t changed any WordPress settings recently, performed any upgrades, or installed any new plugins. I can’t explain it.
I dimly recall seeing a notice from my web host (Dreamhost) a few weeks ago, saying they were updating something… I think MySQL was being upgraded to a newer version. Maybe that’s a factor here?
Whatever the cause, the important question is how to fix this mess. I could go manually edit all the affected pages, but that would be tedious, and I wouldn’t really be confident the problem would stay fixed. Even if I were willing to make manual fixes, it still wouldn’t fix everything, since some of the broken text is in users’ names and comment text rather than in my own page text. For the moment, I’m stumped until I can figure this out.
An Example: Möller
On the ROM-inator page there’s a comment from Kristian Möller. I’m using the explicit HTML entity here for o with umlaut to ensure it renders correctly. Until recently, it also looked correct on the ROM-inator page, but now it appears as Möller, again using explicit HTML entities for clarity. So what happened?
The two-byte UTF-8 encoding for ö is 0xC3 0xB6. The one-byte Latin-1 encoding for à is 0xC3 and for ¶ is 0xB6. So a UTF-8 character is being misinterpreted as two Latin-1 characters, but where exactly is it going wrong? Is the browser misinterpreting the data due to a faulty HTML character encoding meta tag? Is the data stored incorrectly in the WordPress DB? Or is WordPress converting the data on the fly when it retrieves it from the DB to generate the page’s HTML? I did a small test which I think eliminates one of these possibilities.
First I wrote a simple Python 2 program to download and save the web page’s HTML as binary data:
import urllib2
contents = urllib2.urlopen('http://www.bigmessowires.com/mac-rom-inator-ii/').read()
open('mac-rom-inator-ii.html', 'wb').write(contents)
I think this code will download the bytes from the web server exactly as-is, without doing any kind of character set translations. If urllib2.urlopen().read() does any character translation internally, then I’m in trouble. Next I examined the downloaded file in a hex editor:
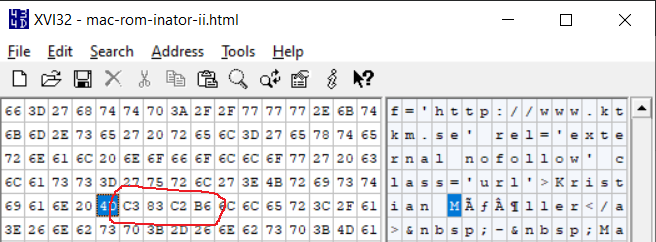
This shows that what the web browser renders as ö is a four-byte sequence 0xC3 0x83 0xC2 0xB6. Those are the two-byte UTF-8 sequences for à and ¶. So this doesn’t look like the web browser’s fault, or a problem with the HTML character encoding meta tag. It looks like the data transmitted by the web server was wrong to begin with, it really is sending à and ¶ instead of ö.
This leaves two possibilities:
- During the MySQL upgrade, 0xC3 0xB6 in the database was misinterpreted as two Latin-1 characters instead of a single UTF-8 character, and was stored UTF-8-ified in the new MySQL DB as 0xC3 0x83 0xC2 0xB6.
- 0xC3 0xB6 was copied to the new MySQL DB correctly, but a DB character encoding preference went wrong somewhere, and now WordPress thinks this is Latin-1 data. So when it retrieves 0xC3 0xB6 from the DB, it converts it to 0xC3 0x83 0xC2 0xB6 in the process of generating the page’s final HTML.
I could probably tell which possibility is correct if I used mysqladmin to dump the relevant DB table as a binary blob and examine it. But I’m not exactly sure how to do that, and I’m a bit fearful I’d accidentally break the DB somehow.
If possibility #1 is correct, then the DB data is corrupted. There’s not much I could do except restore from a backup, or maybe look for a tool that can reverse the accidental character set conversion, assuming that’s possible.
If possibility #2 is correct, then I might be able to fix this simply by changing the faulty encoding preference. I need to find how to tell WordPress this is UTF-8 data, not Latin-1, so just use it as-is and don’t try to convert it.
Read 8 comments and join the conversation8 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
I’m beginning the think Dreamhost’s MySQL update may be the cause. According to the logs, all of BMOW’s MySQL databases were moved to a new server running MySQL 8 on October 6. That was eight days ago. Could these pages have all been broken for eight days without me noticing?
I’ve had very similar problems, on another host, with MySQL updates.
The problem in my case was exactly your possibility #1: originally, UTF-8 characters were stored in a database where character set was actually latin-1. I never noticed this and all appeared to be well because although the database had the wrong idea about what the characters meant, it just stored and retrieved binary data, which PHP which correctly interpreted and displayed as UTF-8. Unfortunately, the MySQL upgrade moved to UTF-8 character set databases, and in that migration the binary data was changed.
I did try a couple of tools for reversing the conversion, but didn’t find them particularly satisfactory.
Chris what did you end up doing? Just living with the broken text for special characters in old pages? Or did you try to manually fix it?
I’ve had a similar problem in Microsoft Dynamics where some records imported from some other systems had invisible (zero-width) spaces, it could induce insanity when debugging. Another reason for better input validation.
Great news: At the recommendation of Dreamhost’s tech support, I was able to fix this problem by adding two extra lines to the wp-config.php file:
define(‘DB_CHARSET’, ‘latin1’);
define(‘DB_COLLATE’, ”);
If I’m not mistaken, this means my Possibility #2 was the correct one: the bytes were carried over correctly from the old DB to the new one, but the type of the database table was set incorrectly.
I’ll admit I don’t understand why this config change works. It seems like it’s the exact opposite of what should have fixed the problem. From everything I’ve read about this issue, the text in the WordPress database is stored as UTF-8 and always has been, regardless of what type the database table says it is. If WordPress thinks the database is UTF-8, and it’s generating a UTF-8 page, then it would presumably use the data as-is and everything would be OK. By forcing WordPress to treat the database as Latin-1 data, it seems like it would cause the exact Latin-1 to UTF-8 conversion error that I’m trying to prevent.
I discovered an unexpected side-effect of this wp-config.php change to DB_CHARSET latin1: for any post or comment text that was entered by me or anyone else between October 6 (the MySQL update) and today, if that text contained any curly quotes, letters with accents, or other international characters, the text now renders with a question mark inside a black diamond shape. For example, this comment from GaryFDes: https://www.bigmessowires.com/2021/09/12/adb-usb-wombat-firmware-0-3-7/#comment-240614 If I attempt to edit the affected post or comment, the WordPress editor just shows an empty edit box with no text. Ugh.
That happened when we moved from MySQL 5.7 to MySQL 8.
The only solution is to do a DB dump on the 5.7 version (or pull from the DB backup) and do a replacement import on the MySQL 8 server after you fix your tables’ encoding to utf8mb4_0900_ai_ci.
It’s a pain in the ass migration if you’re not prepared for it.
nbsp is utf8 c2a0 NOT c280…