

Archive for October, 2021
5V Logic Level Errors
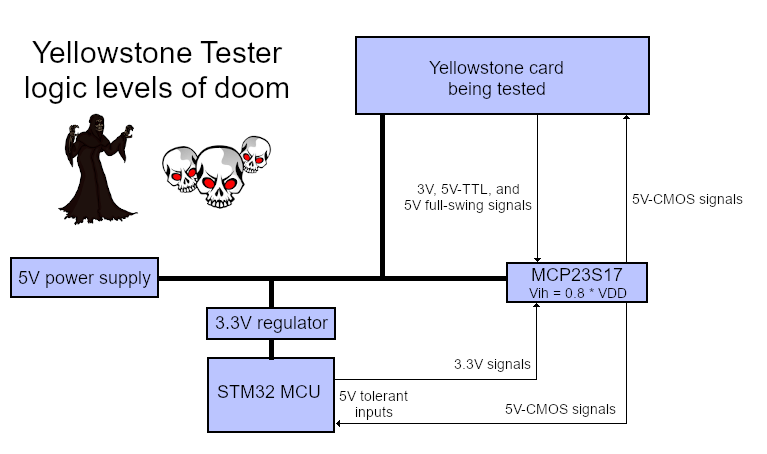
The Yellowstone tester is suffering from the logic level blues. I made a blundering error in its design, which I only discovered now. Like most of my projects, the tester uses a mix of voltages, with the MCP23S17 port expanders running at 5V while the STM32 microcontroller and everything else are running at 3.3V. The card being tested is nominally a 5V device, but it uses TTL signal levels where anything above 2V is considered a logical “1” value. This whole menagerie seemingly worked fine during the tester’s prototyping and development, but it actually has some major problems.
The relevant pins on the STM32 are 5V-tolerant, so that part is fine. Unfortunately I failed to check the input voltage thresholds on the MCP23S17. Now I see that it requires a voltage of at least 0.8 * VDD to detect a logic “1” input value, which means a threshold of 4.0V when VDD is 5V. The STM32 signals are never going to exceed 3.3V, so that’s no good. The so-called 5V signals from the card being tested mostly won’t reach 4.0V either. Some of those signals are driven by 74LS logic with typical high values about 3.4V, and others by 3.3V 74LVC devices.
I’m slightly amazed that I completed the tester prototype, tester PCB, and development of all the tester software without discovering this glaring problem. In fact just yesterday I’d privately declared the tester to be “done”. It was working well, able to program a virgin Yellowstone card and run a large series of functional and electrical tests in just a few seconds’ time. Aside from some rare flakiness I couldn’t reproduce, everything looked good. But then I tried using a different power supply and everything fell apart.
How Did This Ever Work?
With the aid of an adjustable power supply, I eventually found that the tester worked reliably at supply voltages up to 5.05 volts. Above that, the STM32 was unable to communicate with the MCP23S17 port expanders. Some of my other power supplies produce about 5.08 to 5.1 volts with a light load, so that explains why they didn’t work. With a higher VDD, the logic “1” input threshold of the MCP23S17 is also higher, creating a larger shortfall for 3.3V or 5V-TTL signals.
It’s surprising that this ever worked at all. Even at precisely 5.0V, the best case would be a 3.3V signal from the STM32 going into a MCP23S17 input with a 4.0V threshold. A shortfall of 0.7V is pretty large. And yet it did work nicely, at least in this particular circuit, over several weeks of tester development.
Choosing a Voltage
The MCP23S17 port expander can operate with a supply voltage of 5V or 3.3V; I intentionally chose 5V here because the chip interfaces with a card being tested that’s nominally a 5V device, and I was worried about damaging the MCP23S17. Even though most of the output signals from the card should be lower-voltage TTL-level logic signals, at least some of the signals may truly be 5.0 volts. And if the card is defective, which is part of what the tester needs to determine, then any of the card’s signals could be unexpectedly at 5.0V. A chip that’s running at 3.3V can be damaged if 5V is applied to an input pin. If the MCP23S17 has 5V-tolerant inputs then it would be OK, but sadly it doesn’t, so I need to run the chip at 5V to safely read 5V signals. (Probably. See below.)
You can view the MCP23S17 datasheet for the details. In the section for Absolute Maximum Ratings, it says the voltage on all pins should not exceed VDD + 0.6V, and the input clamp current when Vi > VDD should not exceed 20 mA.
How Do I Fix This Mess?
The tester isn’t a product, it’s a tool for developing a product – the Yellowstone disk controller card. I only plan to build three or four testers, and they’ll all be in my possession, or given to whatever PCB assembler I choose to work with. That means I can consider some unconventional fixes here that I would never do on a mass-produced product. If at all possible, I’d like to fix this with some minor surgery to the tester PCB. I really don’t want to design a new tester PCB, add more components and level-shifters, etc. But I need to be confident that the tester is reliable, and if I give one to a PCB assembler, it can’t flake out or give false positives due to minor variations in supply voltage, temperature, or parts substitution on the card being tested.
The fundamental problem is the gap between the 4.0V logic “1” voltage threshold required by MCP23S17, and the lower voltages produced by the STM32 and the card being tested. I either need to raise those voltages up, or lower the MCP23S17 threshold down. None of the possibilities look very promising.
Raising up the lower voltages is basically out of the question. They are what they are, and it would be painful and impractical to insert 5V level shifters on 80-some signals from the card and the STM32.
Lowering the threshold is the only plausible option, which means lowering the supply voltage of the MCP23S17. How much should I lower it, using what method? What other problems might this cause? Should I also lower the supply voltage for the card being tested?
I could lower the MCP23S17 threshold by changing the chip to use a 3.3V supply instead of 5V. But then I would create a new problem where 5V signals might be applied to the chip running at 3.3V, exceeding the absolute maximum rating of VDD + 0.6V and potentially damaging the chip. I could possibly put a series resistor on each of the pins, in order to keep the input clamp current under 20 mA, although this would create some other difficulties and would require making a new PCB.
If I also reduced the supply voltage for the card being tested to 3.3V, it would eliminate the over-voltage concern, but a Yellowstone card won’t work correctly at 3.3V. It has a 74LS244 chip, with a minimum supply voltage of 4.5V.
Diode To The Rescue?
There are no great answers here, but the most promising option I can think of is reducing the supply voltage for the MCP23S17 and for the card being tested to about 4.6V. Using the same voltage for both means there’s no over-voltage risk. At 4.6V the Yellowstone card should still work OK. The reduced voltage would lower the MCP23S17 input threshold to 3.68V, which is still too high, but my tests with the actual hardware show that it should work anyway. The hack-tastic way to get about 4.6V from a 5V source would be using a Schottky or germanium diode to drop a few tenths of a volt. This would be fairly simple to do.
Alternatively I could run the card at 4.6V, but lower the MCP23S17 supply even further to 4.2V, using a second diode. This would still be within the MCP23S17’s absolute maximum rating of VDD + 0.6V, so there shouldn’t be an over-voltage risk so long as the voltages don’t vary too far from their expected values. With a 4.2V supply, the MCP23S17 input threshold would be reduced to 3.36V, which is close enough to 3.3V that I’d be more confident in its reliability.
Complicating all of this is the presence of a 1 ohm sense resistor on the tester’s power supply, which is used for current measurements. Under normal operation, this drops about 50 to 100 mV. If the power supply is nominally 5V, then the MCP23S17 and the card being tested will see a voltage closer to 4.9V.
Another complication is that the 74LS244 on the card being tested will output 5V TTL signal levels, and according to its datasheet, its logical “1” output voltage may be as low as 2.4V. I can’t reduce the MCP23S17 supply voltage far enough to support an input threshold that low. But in practice for a correctly-operating Yellowstone card, and the tester circuitry that’s connected to it, the 74LS244 voltage should be closer to 3.0 – 3.5V, similar to the voltages from the 3.3V STM32.
Using a diode to create intermediate supply voltages is a gross hack, and I don’t like it. It might work during my desk experiments, but then fail later in a different environment. And yet I’m not sure what better alternative I have, unless I’m willing to make major modifications to the tester that will set me back by several weeks. The choices all look bad. I’m embarrassed that I made it this far into tester development without noticing such a fundamental design error.
Read 5 comments and join the conversationThe Yellowstone Tester

I once said I’d spend a maximum of one day on development of an automated tester for the Yellowstone disk controller. Haha, that was so cute. Today marks two months since I began work on the tester. Today was also the first try with the final (I hope) tester hardware. So far it seems to work, mostly.
Yellowstone is an FPGA-based disk controller for Apple II computers. It’s complex enough that fully testing each board is a non-trivial task. Manually testing a large batch of boards would be out of the question, so an automated tester is needed. The heart of the tester design is an STM32 “Blue Pill” board, combined with four Microchip port expander chips to reach a total of 80 I/Os. There are also a few analog sensors for measuring current and voltage, as well as a current switch IC that will disconnect the board being tested if it draws too much current.
Unexplained Current Changes
The ability to measure the supply current was one of the key features of the tester design. Unfortunately it doesn’t seem to work as well as I’d hoped. I was convinced that I needed to measure the combined supply current of the board being tested and the tester itself, in order to capture all possible paths where a short circuit might occur, and that works. So far, so good.
The odd thing is there are unexplained fluctuations in the measured current. With no Yellowstone board present, the current sensor reports about 26 mA used by the tester itself. But if I write some code that sits in a loop repeatedly measuring the current, but doing nothing else, sometimes the current briefly jumps up to 35 or 40 mA. This happens roughly once every second, but not consistently enough to make a reliable pattern. With a Yellowstone board present, the current is higher but similar current measurement fluctuations are still happening. At first I thought this was some deficiency in the STM32 ADC, but other analog measurements by the STM32 don’t have the same issue.
I’m not sure if these current changes are real, perhaps caused by some internal activity of the STM32 briefly increasing the supply current, or if the changes are somehow an artifact of how I’m measuring. Either way, the fluctuations are large enough to undermine most of what I’d planned to use the current measurements for. A measure of 70 mA +/- 25 mA isn’t accurate enough for much diagnosis beyond detecting a hard short-circuit.
Unresponsive ICs
A second problem I encountered is that the Microchip port expander ICs occasionally don’t respond to SPI commands. This often happens when I first turn on the tester after it’s been off for several minutes, but never happens when turning it briefly off and on, or resetting the tester while keeping the power on.
Surprisingly (or maybe it’s not surprising) there seems to be a relationship between the current fluctuations and the unresponsive port expanders. After the board has been off for several minutes, and is then turned on, I’ll very often see an immediate current fluctuation followed by unresponsive port expanders. I’ve added some code when the tester starts up that will repeatedly poll the port expanders until they respond as expected, and this appears to be working for now.
The tester PCB isn’t well designed for probing internal signals to see what’s wrong. Because I already built a breadboard prototype of the tester previously, and thought it was working, this new PCB was designed for small size rather than for debugging. It may require some fancy soldering and old-fashioned detective work to figure out what’s happening here.
Read 6 comments and join the conversationWordPress Latin1 and UTF-8, Part 2

Yesterday I wrote about some BMOW blog troubles displaying special characters and international characters, which was apparently triggered by a recent update to MySQL 8 at my web host. Old pages containing special characters like curly quotes, accented letters, or non-Latin characters were suddenly rendering as garbled combinations of random-looking symbols, whereas they were previously OK. If you read the follow-up comments, you saw that I was eventually able to resolve the problem (mostly) by adding these lines to my wp-config.php file:
define(‘DB_CHARSET’, ‘latin1’);
define(‘DB_COLLATE’, ”);
But I didn’t fully understand what those lines changed, or exactly why this problem appeared in the first place. After some digging in the MySQL database, I think I have a slightly better understanding now.
Back to Kristian Möller
I returned to the example of Kristian Möller, whose name contains the letter o with umlaut. After the MySQL update, the name was appearing incorrectly as Möller. This is what you’d expect to see if the UTF-8 bytes 0xC3 0xB6 for ö were incorrectly interpreted as two separate Latin1 bytes, 0xC3 for à and 0xB6 for ¶.
Using phpmyadmin, I was able to connect to the live WordPress DB, and examine the wp_comments table where this name is stored. The result for comment_id 233746 is shown above, displaying the author’s name as both text and as raw hex bytes. You can see the hex bytes contain the sequence C3B6, which is the correct UTF-8 byte sequence for ö. That’s great news. It means the contents of my database text are correct and uncorrupted UTF-8 bytes. But all is not well – the metadata associated with the table is wrong. It thinks the text is Latin1, and displays it as such in the myphpadmin UI. I was able to confirm this by executing the SQL command:
show create table wp_comments
This echoes back the SQL command that was originally used to create this table, way back in 2007. And lo and behold, part of that original SQL command specified CHARSET=latin1. Ever since then, WordPress has been storing and retrieving UTF-8 text into a Latin1 table in the database. This is bad practice, but it worked fine for 14 years until the MySQL update earlier this month.
Why Does DB_CHARSET latin1 Help?
Defining WordPress’ DB_CHARSET variable to be latin1 sounds like it’s telling WordPress what type of character set is used by the database. But if you think it through, that doesn’t fit the evidence here. If I tell WordPress that my DB data is in Latin1 format, even though as we’ve seen it’s really UTF-8, then I would expect WordPress to convert the data bytes from Latin1 to UTF-8 as it loads them during a page render. That would do exactly the wrong thing; it would cause the very problem that I’m trying to prevent.
I searched for a detailed explanation of precisely what the DB_CHARSET setting does, but couldn’t find one that made sense to me. Most references just say to change the value, without fully explaining what it does.
While I don’t have any strong evidence to support this, my guess is that a MySQL client has a choice of connecting to the MySQL database in Latin1 mode or UTF-8 mode, and this is what DB_CHARSET controls for WordPress. If the client connects as a UTF-8 client but the table is marked as being Latin1, my guess is MySQL automatically translates the data. Normally that would be a good thing, but if UTF-8 data were stored in a table improperly marked as being Latin1, it would cause unwanted and unnecessary character conversions, causing the types of problems I saw on the blog.
Why Did This Break Now?
So what changed during the recent MySQL update to suddenly break this? Why did the problem appear now? Initially I suspected the underlying data bytes had become corrupted during the update, but the hex display from phpmyadmin showed the data bytes are OK.
I can’t say for certain whether the problem was caused by exporting and reimporting my database, or whether it’s due to new behavior in MySQL 8. Now that I think about it, I’m not even certain whether the result I saw from that show create table wp_comments was actually the original SQL command from 2007, or the SQL command from eight days ago when the database was migrated to MySQL 8.
If these database tables were always explicitly marked Latin1, going all the way back to 2007, then I think this character set conversion problem would always have happened too. Or at least it would have happened as soon as I updated to my current version of WordPress, instead of when I updated to a new version of MySQL.
One possibility is that with the old database and old version of MySQL, the character set for the database tables wasn’t explicitly defined. It relied on some database-wide default which just happened to be UTF-8, so everything worked when WordPress connected to the DB as a UTF-8 client. Then during the MySQL 8 update, somehow the tables were explicitly set to Latin1 and the problem appeared.
Another possibility is that the tables were already explicitly Latin1, but WordPress was previously connecting to the database as a Latin1 client, so it worked OK. Since my version of WordPress hasn’t changed recently, this would mean the default database connection type for WordPress must somehow come from the database itself, or the database server, and that’s what changed during the MySQL 8 update.
Whatever the explanation, changing DB_CHARSET now seems like only a temporary solution. I still have UTF-8 data stored in tables that say they’re Latin1, which seems likely to cause more problems down the road. If nothing else, it makes the output display incorrectly in the phpmyadmin UI. A full solution will probably require some more significant database maintenance, but I hope to postpone that for a while.
Read 3 comments and join the conversationNon-Breaking Spaces and UTF-8 Madness

A few months back I wrote about some web site troubles with the HTML entity, non-breaking spaces, and UTF-8 encoding. A similar problem has reared its head again, but in a surprising new form that seems to have infected previously-good web pages on this site. If you view the Floppy Emu landing page right now, and scroll down to the product listing details, you’ll see a mass of stray  characters everywhere, screwing up the item listings and making the whole page look terrible. Further down the page in the Documentation section, the Japanese hiragana label that’s supposed to accompany the Japanase-language manual appears rendered as a series of accented Latin letters and square boxes.
The direct UTF-8 encoding for a non-breaking space (without using the entity) is C2 80. Â is Unicode character U+00C2, Latin capital letter A with circumflex. So somehow the C2 value is being interpreted as a lone A with circumflex character rather than part of a two-byte sequence for non-breaking space.
The strangest part of all this is that the Floppy Emu landing page hasn’t been modified since September 6, and I’m sure it hasn’t looked this way for the past month. In fact the most recent archive.org snapshot from September 8 shows the page looking fine. So what’s going on?
I’ve noticed a related problem with some other pages on the site. The Mac ROM-inator II landing page hasn’t been modified in six months, but it too shows strange encoding problems. The sixth bullet point in the feature list is supposed to say Happy Mac icon is replaced by a color smiling “pirate” Mac, with the word pirate in curly double-quotes. In the most recent archive.org snapshot it looks correct. But if you view the page today, the curly quotes are rendered as a series of accented letters and Euro currency symbols. There are similar problems elsewhere on that page, for example in the second user comment, Kristian Möller’s name is rendered incorrectly.
These problems are visible in all the different browsers I tried. And none of them seem to correspond to any specific change I made in the content of those pages recently.
I’m not a web developer or HTML expert, but I’m wondering if the header of all my HTML pages somehow got broken, and it’s not correctly telling the web browsers to interpret the data as UTF-8. But when I view the page source using the Chrome developer tools, the fourth line looks right:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
And what’s more, Unicode characters in this very blog post appear to render just fine. For example I can copy-paste those hiragana characters from the archive.org snapshot of the Floppy Emu page, and paste them here without any special encoding tricks, and they render correctly:
??????????????
Nevermind, I’m wrong. I can paste those characters into the WordPress editor, and they appear correctly, but as soon as I save a draft or preview the page they turn into a string of question marks. I’m sure that direct copy-and-paste of this text used to work, it’s how I added this text to the Floppy Emu page in the first place.
So if the character set is configured correctly in my pages’ HTML headers (which I could be wrong about), what else could explain this? The alternative is that the text is stored in a broken form in the WordPress database, or is being broken on-the-fly as the page’s HTML is generated. Perhaps some recent WordPress action or update caused the text of previously-written pages to be parsed by a buggy filter with no UTF-8 awareness and then rewritten to the WordPress DB? But I haven’t changed any WordPress settings recently, performed any upgrades, or installed any new plugins. I can’t explain it.
I dimly recall seeing a notice from my web host (Dreamhost) a few weeks ago, saying they were updating something… I think MySQL was being upgraded to a newer version. Maybe that’s a factor here?
Whatever the cause, the important question is how to fix this mess. I could go manually edit all the affected pages, but that would be tedious, and I wouldn’t really be confident the problem would stay fixed. Even if I were willing to make manual fixes, it still wouldn’t fix everything, since some of the broken text is in users’ names and comment text rather than in my own page text. For the moment, I’m stumped until I can figure this out.
An Example: Möller
On the ROM-inator page there’s a comment from Kristian Möller. I’m using the explicit HTML entity here for o with umlaut to ensure it renders correctly. Until recently, it also looked correct on the ROM-inator page, but now it appears as Möller, again using explicit HTML entities for clarity. So what happened?
The two-byte UTF-8 encoding for ö is 0xC3 0xB6. The one-byte Latin-1 encoding for à is 0xC3 and for ¶ is 0xB6. So a UTF-8 character is being misinterpreted as two Latin-1 characters, but where exactly is it going wrong? Is the browser misinterpreting the data due to a faulty HTML character encoding meta tag? Is the data stored incorrectly in the WordPress DB? Or is WordPress converting the data on the fly when it retrieves it from the DB to generate the page’s HTML? I did a small test which I think eliminates one of these possibilities.
First I wrote a simple Python 2 program to download and save the web page’s HTML as binary data:
import urllib2
contents = urllib2.urlopen('http://www.bigmessowires.com/mac-rom-inator-ii/').read()
open('mac-rom-inator-ii.html', 'wb').write(contents)
I think this code will download the bytes from the web server exactly as-is, without doing any kind of character set translations. If urllib2.urlopen().read() does any character translation internally, then I’m in trouble. Next I examined the downloaded file in a hex editor:
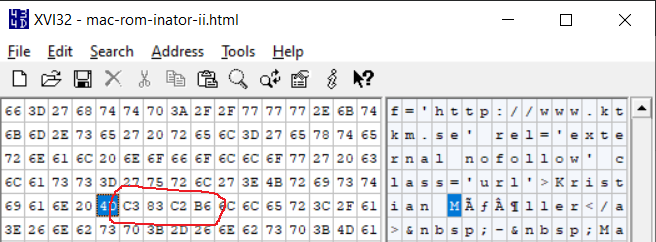
This shows that what the web browser renders as ö is a four-byte sequence 0xC3 0x83 0xC2 0xB6. Those are the two-byte UTF-8 sequences for à and ¶. So this doesn’t look like the web browser’s fault, or a problem with the HTML character encoding meta tag. It looks like the data transmitted by the web server was wrong to begin with, it really is sending à and ¶ instead of ö.
This leaves two possibilities:
- During the MySQL upgrade, 0xC3 0xB6 in the database was misinterpreted as two Latin-1 characters instead of a single UTF-8 character, and was stored UTF-8-ified in the new MySQL DB as 0xC3 0x83 0xC2 0xB6.
- 0xC3 0xB6 was copied to the new MySQL DB correctly, but a DB character encoding preference went wrong somewhere, and now WordPress thinks this is Latin-1 data. So when it retrieves 0xC3 0xB6 from the DB, it converts it to 0xC3 0x83 0xC2 0xB6 in the process of generating the page’s final HTML.
I could probably tell which possibility is correct if I used mysqladmin to dump the relevant DB table as a binary blob and examine it. But I’m not exactly sure how to do that, and I’m a bit fearful I’d accidentally break the DB somehow.
If possibility #1 is correct, then the DB data is corrupted. There’s not much I could do except restore from a backup, or maybe look for a tool that can reverse the accidental character set conversion, assuming that’s possible.
If possibility #2 is correct, then I might be able to fix this simply by changing the faulty encoding preference. I need to find how to tell WordPress this is UTF-8 data, not Latin-1, so just use it as-is and don’t try to convert it.
Read 8 comments and join the conversationApple II Pascal Booting Problems

Thanks to beta tester Bryan V., I’ve discovered that Apple II Pascal disks don’t boot normally with the prototype Yellowstone disk controller card. This includes the Pascal master disk as well as other disks built on Pascal, including Fortran, “Apple at Work”, and the game Wizardry. These disks begin to boot normally, and several tracks’ worth of data are loaded from the disk successfully, but then they halt with an error like “SYSTEM.PASCAL not found” or “Insert boot disk with SYSTEM.PASCAL”. These same disks work OK when Yellowstone emulates a plain Disk II controller card, so it looks like a ROM/software issue rather than hardware. For what it’s worth, a Laser UDC card also shows the same problem when attempting to boot these same Pascal disks.
The behavior is strange, because for every other disk I’ve seen with a ROM dependency on the Disk II controller card, it crashes or freezes during boot when it tries to use the missing Disk II controller card ROM. But the Pascal disks are failing with a nice error message about a missing file, making me think the problem is probably something else.
One clue: I found three Pascal-based disks that fail to boot even with a real Disk II controller card, on an enhanced //e: Pascal 1.1 Apple0 680-0003-01.dsk, Apple Pascal Basics and Integer & Applesoft II, and Pascal Profile Manager. I’m unsure if there’s a missing hardware requirement or if I’m doing something wrong. Even with a standard Disk II controller card these disks halt with the messages “No file SYSTEM.APPLE”, “Insert BASIC disk and press any key”, and “Insert boot disk with SYSTEM.PASCAL”, respectively.
I’m not very familiar with the low-level details of Apple II Pascal disks, or how Pascal does disk I/O. Maybe it expects a different set of API entry points in the disk controller ROM than ProDOS? Or maybe there’s something else unique about its disk I/O behavior?
The good news is that these Pascal-based disks do work OK when Yellowstone is configured in its Disk II controller emulation mode, but I’d like to understand why the normal Yellowstone mode doesn’t work.
Read 11 comments and join the conversationTech Support Dilemmas

When I first began selling hardware to other vintage computer collectors, I never gave tech support much thought. I imagined I could design something, build it, sell it to somebody, and they’d happily go use it. End of story. Reality has proven different. Today I spend more time answering tech support questions from customers and potential customers than on any other aspect of the business. I get large amounts of mail, often with questions that are long and complex and need considerable time to answer properly. It’s a challenge for which I’ve yet to find any good solution.
A portion of the tech support is really sales support – questions about ordering and shipping. If you’ve been through the BMOW store in the past six months, you may have seen there’s a new person helping with these kinds of inquiries, which has been a huge help. But even after these are filtered out, the tech support load remains high.
RTFM?
Can I solve the tech support problem with more documentation? I’ve put a lot of time into the BMOW product documentation, particularly for the Floppy Emu. Every customer receives a printed one-page quickstart guide covering the basics, with a link to the full instruction manual on the web. Whenever the same question gets asked two or three times, I add the answer to the instructions or the quickstart. At least in theory, everything anyone would ever want to know should be covered in the documentation.
Yet I can’t escape the basic fact that there’s a lot of inherent complexity with these old computer systems and the products designed for them. In the case of the Floppy Emu, there’s a ton of ground to cover in the instructions between three different computer families, a dozen different drive emulation modes, different types of disk images, different operating systems, different ways of connecting to the computer, interactions with other drives, and much more.
The wall of documentation can be daunting. Even with the one-page quickstart that’s bundled in the box, it can be too much for some people. They throw up their hands and reach out to tech support (me) for assistance. In many cases I’m able to gently point people back to the relevant section of the manual: “It sounds like you may need to select a different disk emulation mode. Please see section 3.2 of the instruction manual for details.” But sometimes people get upset or offended if I refer them to the manual. I had one angry customer send me a video message in which he outright refused to read the instructions, insisting the he didn’t want to learn Computer Nerd 101 or get a history lesson in Apple computer models.
Whose Problem Is It?
A second challenge is simply identifying who or what is responsible when something doesn’t work as expected. The line between questions about BMOW hardware and questions about general usage of the Apple II or Macintosh is often blurry. For many customers, they’ve hauled an old computer out of their dusty attic, purchased a bit of BMOW hardware to run with it, and are using the machine for the first time in thirty years. If a questions arises, it will often come to me first, regardless of the source or the issue. I’ll get general questions about the Apple IIc, or about Macintosh System 7, or StuffIt. Some requests ask how to use particular software programs, or how to eject a disk, or reboot the computer. Much of this is now covered in the Floppy Emu instruction manual, since they’re common questions even if they’re not features of BMOW hardware.
What’s more puzzling are the questions about unrelated third-party products. If someone contacted me once with a BMOW tech support question and found my answer helpful, sometimes they’ll contact me again later even when their question has nothing to do with BMOW. I get a surprising number of tech support requests about the SCSI2SD. I’ve also had support requests asking about RAM upgrades, joysticks, and other peripherals. Sometimes I know the answer, sometimes I don’t. Sometimes I’ll decline to answer even if I know it, which makes me feel like a jerk, but I need to politely discourage this kind of tech support usage. Usually I’ll point people to another suggested information source instead.
This challenge isn’t limited to the Floppy Emu. The original Mac ROM-inator kit for the Mac 128K, Mac 512K, and Mac Plus was also a big source of general questions about classic Macintosh usage and problems. As a low-cost kit generating a high level of tech support, it just didn’t make sense, and this was one of the primary reasons the original ROM-inator kit was eventually discontinued.
Solutions?
I’m unsure how other small businesses solve this problem. Some of them may sell products that are so simple, they don’t need much tech support. Or their tech support is just weak, and they willingly suffer the reputational hit, choosing it as the least bad option compared to hours and hours of support time.
Documentation can always be improved, so that’s another area I can work on. I’m discovering that technical writing is a critical skill, and it’s not enough to simply have the necessary information in there somewhere – it needs to be presented clearly, and in a logical order. And even if the documentation is perfect, some people simply don’t want to read it.
Many companies now have support forums where customers answer questions from other customers, and the business itself is mostly or entirely absent from the conversation. This is certainly one way of reducing a company’s tech support requirements, but from my personal experience the customer experience is almost universally poor. Discussions often devolve into angry denouncements of the business, like “why isn’t (company) saying anything about this???” At worst, it can create the impression that customers have been cast out into the wilderness to fend for themselves. That’s not good.
I’ll keep searching for better solutions. Until then, I’m off to visit the tech support queue…
Read 4 comments and join the conversation