

Archive for June, 2021
NASA Struggles to Fix Hubble Space Telescope’s 1980s Computer

Did anybody else see this week’s news about problems with Hubble’s 80s-vintage onboard computer and think: *gasp* My moment in life has arrived! Hold my beer.
“Hello, NASA? Did you guys try PR#6? Sometimes the boot disk gets dust on it; ask an astronaut to blow it off and then reboot. Hello? Hello? Why did they hang up?”
The Hubble’s computer is actually an NSSC-1, an 18-bit machine with 64KB memory. The version on Hubble is likely built from a few dozen discrete MSI chips. There are two fully redundant computers on board, and four independent 64KB memory modules, any of which can be enabled or disabled from the ground in the event of a problem. But 30 years of bombardment by cosmic rays will take a toll on the hardware.
Be the first to comment!Yellowstone Glitch, Part 6: This Is Getting Ridiculous

Driving 11111111 from RAM through the ‘245 onto the data bus is causing trouble. I can see this clearly – other chips begin to glitch the moment the ‘245 is enabled. But driving 11111111 from the FPGA through the ‘245 onto the data bus is apparently OK, and driving other values from RAM is also OK. I can’t explain why. I’ve added extra wires from the power and ground pins of the ‘245 and the RAM directly to the voltage regulator, and added extra bypass capacitors, all in an attempt to satisfy the rush of current. It’s still not behaving how I’d expect.
During a bus cycle, first IOSTROBE goes low, then about 140 ns later the ‘245 is enabled for output. The bus cycle ends after 500 ns when IOSTROBE goes high. I finally captured some oscilloscope traces of a bus cycle when RAM outputs 11111111, and it doesn’t look good. All of the traces shown here are referenced to a ground point on the Apple II motherboard. As mentioned previously, some of the over- and undershoot seen on the scope may be due to my poor probe setup, rather than the signal itself.
- Blue (Ch4) is address line A1. It’s a 5V input from the Apple II, and it shouldn’t be changing during this bus cycle.
- Yellow (Ch1) is the 3.3V supply voltage, measured at the VCC pin of the ‘245.
- Cyan (Ch2) is IOSTROBE, and marks the boundaries of the bus cycle.
- Pink (Ch3) is the GND voltage, measured at the GND pin of the ‘245, relative to the Apple II motherboard.

When IOSTROBE first goes low, the RAM is enabled and begins drawing 85 mA, but nothing else happens. This causes some small noise in the 3.3V and GND supplies, but nothing terrible. Then after 140 ns when the ‘245 is enabled, all hell breaks loose. There’s major oscillation on the 3.3V and GND supplies, with a period of 20-30 ns, lasting about 100 ns. But what’s really puzzling is the noise on A1! This is an input coming from the Apple II, off-board, so it shouldn’t be affected by power supply problems local to Yellowstone. It also shows a major erroneous spike when IOSTROBE goes high and the bus cycle ends. This is the moment when both the ‘245 and the RAM are disabled. What the hell?
Compare this to a bus cycle reading 11111111 from ROM (the FPGA) instead of from RAM:

When the ‘245 is enabled, the noise on the 3.3V and GND supplies isn’t nearly as bad as before. But the noise on A1 is still very bad.
Here’s an example of reading 00000000 from RAM:

And reading 00000000 from ROM (FPGA):

In all four cases, I captured many bus cycles and used the example that looked worst. Many of them looked mostly fine. I still think it’s important what residual value is remaining on the bus capacitance from the previous bus cycle – some residual values cause trouble and others don’t.
Conclusions?
What have we learned from all this? First, there’s some problems no matter what value is driven, and no matter what the source. It’s just that 11111111 from RAM is the worst, but even 00000000 shows problems. Second, my addition of extra power and ground wires and extra bypass capacitors clearly hasn’t prevented some major signal integrity problems whenever the ‘245 is turned on, and when it’s turned off. I’m unsure if it’s due to violating the maximum output voltage of the ‘245, or just due to a large but expected amount of current flowing and stopping. The fact that signal problems occur when the ‘245 is turned off as well as when it’s turned on makes me think it’s probably just large but expected current flows.
The real puzzler is what’s happening with A1. How could a problem with the Yellowstone board affect a signal input from the Apple II?
One possibility is Yellowstone’s PCB routing. All eight of the data bus output traces cross under the traces for address lines A0 to A6. Here you can see the eight red data bus traces coming from the left, passing through vias and terminating at edge connectors on the back of the PCB. Address lines A0 to A6 are the red traces coming from the top and terminating at edge connectors on the front of the PCB.
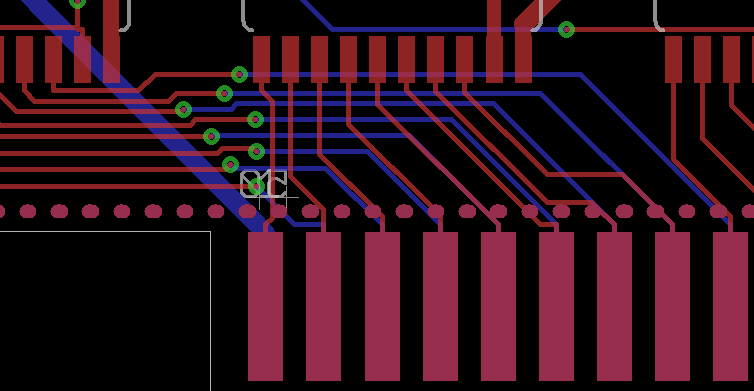
Maybe when all eight data bus values change at once, the combined change in electric field is enough to influence the address traces on the opposite site of the PCB. Maybe. But I’ve also seen similar noise on other Apple II inputs like IOSTROBE, whose traces are far away from the data bus traces.
Another possibility is that the Apple IIgs is actually the culprit, and it can’t handle the current spike without problems. The sudden current causes weird behavior on the logic board, creating major noise on the peripheral input signals. This might also explain why 11111111 from RAM is worse than 11111111 from the FPGA, because the RAM draws extra current when it’s enabled, so the total current consumption of the board will be highest when RAM is enabled and the ‘245 is outputting all 1 bits. But if the IIgs were choking on the current, I would expect to see weird bugs and lockups, and I haven’t.
No matter what, the clues seem to be pointing towards a solution of reducing the current through the ‘245. My trick of pre-driving 10101010 does this, but there must be better ways. I’ll try some other logic families besides 74LVC that still work for 3.3V to 5V level translation, but with slower slew routes and a reduced peak current. I need a 3.3V chip with 5V tolerant I/Os but slower, softer-driving outputs than 74LVC. Failing that, I’ll keep the 74LVC245 as the bus driver, but add series resistors to the data bus traces in order to limit the current.
Read 12 comments and join the conversationYellowstone Glitch, Part 5: Fix Signal Integrity With This One Weird Trick
All the clues surrounding Yellowstone’s glitching problems seem to point towards a power supply problem with the ‘245 bus driver and/or the SRAM. The good news is that I now have a “solution” that seems to fix the glitches, and gets the board functioning normally. The bad news is that I don’t understand why the solution works, or what the underlying problem is, so I can’t be confident that it’s really gone.
In part 4 I described how the glitch occurs occasionally if the value $FF is read from RAM. Something goes wrong when driving all 1 bits from RAM onto the data bus. So my solution is to handle RAM reads like this:
- Make the FPGA output the value $AA / 10101010
- After 70 ns, enable the ‘245 bus driver to put that value on the Apple II bus
- After another 70 ns, turn off the FPGA output and enable the RAM to get the real value
- At the end of the bus cycle, disable the ‘245 and the SRAM
And it works! I no longer see glitching on the logic analyzer, and Yellowstone now seems to work normally for booting disks on the Apple IIgs. But why does this trick help?
One possibility is a residual 5V on the data bus from the previous bus cycle’s value. When the 74LVC245 turns on its outputs and tries to drive 3.3V onto the bus, but finds that the bus capacitance is already charged to 5V, this will briefly create a condition that violates the maximum output voltage rating of the chip. Maybe it causes unexpected behavior or chip damage. If that’s what’s happening, then pre-driving 00000000 before the real RAM value instead of 10101010 should be best, because it will avoid the condition where the chip tries to drive 3.3V into a 5V bus capacitance. But I tried this, and it actually made the glitching worse than it was originally. Hmm. That would seem to rule out this explanation.
A second possibility is that there’s no violation of any maximum ratings, but that driving 11111111 onto the data bus simply demands a large amount of instantaneous current, which the bypass capacitor and the voltage regulator are unable to handle. So the local 3.3V voltage sinks down and/or local GND voltage gets pulled up, and some chips glitch. The ‘245 and the RAM are the furthest chips away from the voltage regulator on the PCB, so this would make sense. Pre-driving 10101010 before the actual RAM value helps smooth out the supply current spike by preventing all the outputs from changing to 1 at the same time. Any other pattern with four 1 bits should serve the same purpose.
If this is indeed what’s happening, then the real solution ought to be ensuring the ‘245 and the RAM both have really good 3.3V and GND connections back to the voltage regulator and to the board’s bulk capacitor, and also adding some larger value bypass capacitors directly next to each chip. So I did some surgery on the board, adding a 10 uF SMD ceramic bypass capacitor next to the existing 0.1 uF for the ‘245, and running 3.3V and ground wires directly back to the regulator, but it didn’t fix the glitching. That was a surprise, and it would seem to rule out this explanation too.
Now I’ve apparently eliminated both of the plausible explanations for the glitching behavior, leaving me with nothing. Either my testing is flawed, or something else is happening here that’s different from either of these explanations. It’s all driving me slowly insane. Although I now have a work-around solution in pre-driving 10101010, I don’t want to move on until I can explain all this behavior and have some confidence that the problem won’t return.
Read 7 comments and join the conversationYellowstone Glitch, Part 4: The Plot Thickens
I’ve discovered something very useful about the signal glitching problem with Yellowstone: I can reproduce the problem (or a form of it) without booting a disk, and even without any disk drive attached. After many hours, I think I’ve narrowed it down to this:
If the CPU reads the value $FF from any location in Yellowstone’s RAM, it might cause a glitch on many different signals simultaneously.
Reading $FF from Yellowstone’s ROM doesn’t cause any trouble. Reading other values with seven 1-bits from Yellowstone’s RAM may cause a glitch, but it’s less likely than when reading $FF. Reading values with six or fewer 1-bits from RAM doesn’t seem to be a problem.
I wrote a tiny program to store $FF in RAM and repeatedly read it back in a loop, and then examined a variety of board signals while the program was running. There were nasty glitches everywhere. But when I zoomed out the time scale, I noticed that the glitches appeared in regular clusters. And zooming out still further, I made this discovery about the behavior when continuously reading from Yellowstone RAM:
Glitches appear in a roughly regular pattern with a 16.5 ms period. Within that pattern is a second pattern with a 62 us period.
Yup, it’s a 60 Hz pattern with a 16 KHz pattern overlaid. Smells like NTSC video! But I don’t think it’s literally video interference, as I’ll explain in a moment. My guess is it’s an issue with data bus traffic related to the Apple IIgs video refresh.
One more important detail:
Glitches appear almost immediately after the ‘245 is enabled to drive the data bus, and can continue for a long time (hundreds of nanoseconds).
Speculation and Guesses
I’m pretty confident about everything up to this point. The rest is an educated guess:
When the ‘245 is enabled to drive a $FF value onto the data bus, it somehow causes signal integrity problems elsewhere. This might be due to undiagnosed bus fighting, but my hunch is that it’s actually due to the capacitance of the Apple II data bus. From what I’ve read in a few reference books, the bus has a pretty high capacitance, and this is a “feature” that holds the last value on the bus even after nothing is driving it anymore.
If the last value on the bus was 00000000, and the ‘245 tries to drive 11111111, there will be a brief rush of current while the bus capacitance is charged up. But the bypass capacitor on the ‘245 should handle this, I think. Adding more / different capacitors to the ‘245 on my board didn’t seem to help.
I suspect the real problem might be exceeding the maximum ratings of the 74LVC245. It’s a 3.3V chip with 5V tolerant inputs, but the output voltage is only safe to VCC + 0.5V. If the chip turns on its outputs to drive 3.3V onto the data bus, but sees there’s already 5V there, the absolute maximum rating will be exceeded. Maybe this results in 5V feedback back into the 3.3V power supply? Which results in horrible glitching everywhere else?
The Apple II video circuitry uses the data bus to read video memory, in between each 6502 or 65816 CPU cycle. That means the last value on the bus will be determined by whatever the video circuitry just read. This would explain why the glitching appears to follow a pattern with a frequency that matches NTSC video.
Holes in the Theory
This sounds sort of plausible. But when I measured the 3.3V supply with an oscilloscope, the few swings I saw didn’t seem large enough to cause problems like what I’m seeing. Maybe I need to look harder.
This theory also wouldn’t explain why glitches sometimes continue for hundreds of nanoseconds. Surely the parasitic bus capacitance should be fully charged or discharged in less time than that? Maybe it induces some kind of unwanted oscillation in the voltage regulator or other components?
The biggest flaw with this theory is that it doesn’t explain why the glitches only happen when reading from RAM, not ROM. The RAM and the FPGA (which contains the ROM) are connected in parallel to the ‘245. From the viewpoint of the ‘245, outputting a $FF byte from RAM is identical to an $FF byte from ROM.
RAM Supply Current Spikes
The SRAM datasheet reveals that the chip’s supply current is 85 mA when /CS is asserted, but as low as 2 mA when /CS isn’t asserted. My design is constantly switching /CS on and off for RAM accesses, so that’s going to create a very spiky current demand.
As before, I think the bypass capacitor on the SRAM should handle the spiky current, and adding more capacitance there didn’t seem to help my prototype board. So this doesn’t quite fit, but it’s the only reason I can think of why RAM access would behave differently from ROM access.
Confirming and Maybe Fixing
Putting everything together, the theory looks like this: when the ‘245 drives 11111111 onto the data bus, it creates a whole lot of power supply noise, possibly due to exceeding the output voltage maximum rating. Normally this noise isn’t enough to cause problems, but if the SRAM /CS is asserted a short time earlier, it will also create a supply current spike when that 85 mA load is switched on. The combination of these two effects is what pushes the Yellowstone board over the line into glitching territory. And the glitches continue for a couple of hundred nanoseconds, because of… reasons I don’t know.
When I write everything out, this theory actually sounds pretty shaky. But it’s the best I have right now.
What evidence would help prove or disprove this theory? Better measurements of the 3.3V supply? Bus voltages? Current into and out of the ‘245? Some of that would be difficult to measure.
Assuming this theory is right, how might I fix it? It seems like the exact type of problem that bypass capacitors should help solve, but so far I’ve seen no improvement when adding extra bypass caps. Maybe I need to try harder, with different capacitor values and in different locations on the board.
Another fix might be to replace the 74LVC245 with a 74LVT245. It’s basically the same chip, but with a higher current drive and with outputs that are safe up to 7 volts. If I’m causing problems by exceeding the max output voltage of the 74LVC245, swapping for the LVT should resolve it.
Other options might be to use a dual-supply 74LVC8T245, or to add series termination resistors, but both of those ideas would require designing and building a new board revision. Without more confidence that it would actually fix the problem, I’m reluctant to do that yet.
Read 15 comments and join the conversationYellowstone Glitch, Part 3: Train Wreck
This Yellowstone glitching problem has gone from puzzling to frustrating to potentially project-ending. I’m still not exactly sure what’s going wrong, let alone how to fix it, and I’ve nearly exhausted all my troubleshooting ideas. In the hopes that maybe the problem could be explained by damaged hardware, I assembled an entirely new Yellowstone card from spare parts, but it fails in exactly the same way as the original card. Grrrr.
Let’s review the facts here. In limited testing, Yellowstone appears to work great on the Apple IIe for controlling any type of disk drive: Smartport drives like the Unidisk 3.5 or Floppy Emu’s hard disk mode, dumb 3.5 inch drives like the Apple 3.5 Drive, and 5.25 inch drives. On the Apple IIgs it works for Smartport drives and 5.25 inch drives, but dumb 3.5 inch drives almost always result in a crash while booting the disk.
The immediate cause of the crash looks like this: While the computer is executing code from the Yellowstone’s onboard ROM in address range $C800-$CFFF (which is actually internal FPGA memory), the card suddenly thinks it’s been deactivated and that it’s no longer in control of that address range. So it stops outputting bytes, the CPU reads and executes random garbage bytes, and there’s a crash. Yellowstone thinks it was deactivated because it thinks the CPU put the address $CFFF on the bus, which deactivates all peripheral cards. But that’s not true.
For unknown reasons, this problem only ever occurs during a clock cycle when the CPU is reading from Yellowstone’s SRAM chip, although I don’t have any idea why that’s relevant. Nor can I explain why it only happens for 3.5 inch disk drives, and only on the Apple IIgs.
At first I thought it was a clock glitch on Q3 causing Yellowstone to incorrectly see and react to a phantom $CFFF address, and I captured some Q3 glitches with the logic analyzer. But then I started noticing other glitches on other signals, some of which appear tens of nanoseconds before the Q3 glitch. So it’s more likely that the Q3 glitch is a symptom of some other problem, rather than the root cause.
My best guess (but only a guess) is there’s a problem with the 3.3V power supply, and some transient noise on the supply is inducing glitching in multiple locations. With an oscilloscope, I observed a few instances where the 3.3V supply very briefly swung as high as 3.84V and as low as 2.76V, at the same time the data bus driver was enabled. But I’m a bit suspicious of those numbers. My oscilloscope always seems to show wild ringing on signals, no matter what project I’m working on, so I’m thinking that’s at least partly the result of my probes or the way I’m taking the measurements. I made several changes to the bus driver, including advancing and delaying the enable timing, and adding more bypass capacitors with various values, but nothing seemed to make a difference in preventing the glitches.
Without being able to clearly characterize exactly where and when the problem is occurring, my hopes for fixing it are low. I still don’t know whether what I’ve observed on the logic analyzer is the cause, or only a symptom.
The bad news is that I’m running out of ideas about what else to try. This train is headed down the wrong track, and the next stops are Frustrationville, Dead-End Town, and Abandon City.
Read 15 comments and join the conversationClock Glitch, Part 2
I’m still chasing the cause of a rare Q3 clock glitch on the Yellowstone board. I’ve collected some more data that may help point to the underlying cause. It’s quite a puzzle, but I like a good mystery.
I began with some armchair reasoning. A glitch happens when some signal changes state and accidentally causes another signal to change state too, usually due a defect in the board’s design. Glitches don’t appear when all the signals have a constant value. My earlier observations showed that the Q3 glitch always occurred during a read from Yellowstone’s SRAM chip, about 50 to 150 ns after the falling edge of Q3. So what other signals would be expected to change state 50 to 150 ns after the falling edge of Q3? Those would seem to be the only possibly culprits.
I reviewed the Yellowstone design, and the list of signals that could change state during that time window is pretty short. First among them is 7M: a 7 MHz clock that’s provided by the Apple II. I examined what 7M was doing at the time of the glitches, but there was no particular phase relationship I could find between 7M and the Q3 glitch, after reviewing many example glitches. So I think 7M can be crossed off the list. Next is Phi1, another Apple II clock. But reviewing the trace showed that Phi1 never changes during the time period of interest.
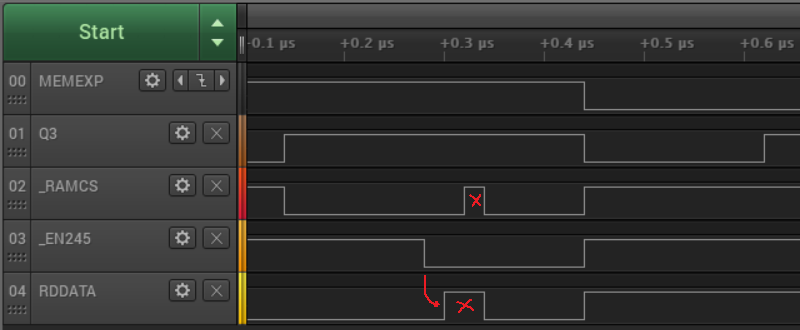
That only left a couple of asynchronous signals as possibilities, including RDDATA, the incoming bit stream from the disk. RDDATA could change state at essentially any time. When I captured a trace including the glitch and RDDATA, I found something very interesting:

I call this the multi-glitch. You can see there’s a glitch on RDDATA before the falling edge of Q3, with a simultaneous glitch on RAMCS, and the glitch on Q3 happening about 140 ns after that. This tells a different story than my earlier data, because it shows that the problem started before the falling edge of Q3. It means the Q3 glitch is just a manifestation of something that went wrong a moment earlier.
At first I thought there was a simple explanation for this: something bad on RDDATA causing cascading problems elsewhere. But although a glitch on RDDATA would cause disk data to get corrupted, it shouldn’t have any effect on RAMCS or Q3. Instead I think all three signals must be getting impacted by sudden fluctuations in the power supply. At least that’s the only explanation I can think of for three signals to glitch at the same time, when they’re logically unrelated and physically separated on the PCB.
The glitching on RDDATA and RAMCS looked unrelated to the actual data on RDDATA, but it always happened about 160 ns after the rising edge of Q3. Applying the same armchair reasoning as before, I wondered what other signals might be changing state when the glitch occurred, and this time I had a better answer. That’s about 20 ns to 80 ns after the board’s 74LVC245 bus driver is enabled, pushing Yellowstone’s output byte onto the Apple II data bus:
Now I think we may finally be getting close to an answer. It would make a lot of sense to see sudden fluctuations in the power supply shortly after the 74LVC245 is enabled. If there’s bus contention, that’s the moment when it’s going to appear. And even if there’s not bus contention, if the bus driver’s outputs simultaneously all change from 0 to 1 or vice-versa, it can create a big current spike. This is exactly why bypass capacitors are important, to smooth out power supply noise from this type of event.
Bus contention on this ‘245 was exactly what caused the downfall of my original Yellowstone effort back in 2017-2018. It was more than two years before I came back to it, identified the bus contention, and fixed it. Or did I? Maybe it’s not completely fixed? So I tried making some changes to advance or delay the timing of the ‘245 enable signal, but it didn’t seem to have any effect on the glitching. Hmm.
Maybe there’s no bus contention, but it’s still a problem when all the bus driver’s outputs change at once. I’m not sure why that problem would only happen when the SRAM chip is being read, but maybe the SRAM also places a sudden load on the supply rail, and the combination of the two effects is too much. Do I have insufficient bypass capacitance on my ‘245 bus driver chip? It’s a 0.1 uF ceramic capacitor, connected by short traces to the chip’s power and ground pins. I could try soldering in some additional capacitors, or capacitors of a different type.
Whether it’s bus contention or something else causing power supply fluctuations, I ought to be able to see the fluctuations on the 3.3V supply at the moment of the glitch. But when I looked, I didn’t see anything. That could be because I used the analog mode of my logic analyzer, which has a very limited bandwidth, rather than a true oscilloscope. I need to keep looking. I feel like I’m getting closer to solving this puzzle, but still not quite there.
There’s still one other possible explanation here: a damaged chip resulting from my earlier fiasco when D5 was accidentally shorted to the 3.3V supply. That could have damaged the ‘245, the SRAM, or the FPGA. They all seem to be working OK now, but maybe there’s some hidden damage, and under the right conditions the ‘245 will go crazy and draw way too much current.
Read 1 comment and join the conversation