

Clock Glitch, Part 2
I’m still chasing the cause of a rare Q3 clock glitch on the Yellowstone board. I’ve collected some more data that may help point to the underlying cause. It’s quite a puzzle, but I like a good mystery.
I began with some armchair reasoning. A glitch happens when some signal changes state and accidentally causes another signal to change state too, usually due a defect in the board’s design. Glitches don’t appear when all the signals have a constant value. My earlier observations showed that the Q3 glitch always occurred during a read from Yellowstone’s SRAM chip, about 50 to 150 ns after the falling edge of Q3. So what other signals would be expected to change state 50 to 150 ns after the falling edge of Q3? Those would seem to be the only possibly culprits.
I reviewed the Yellowstone design, and the list of signals that could change state during that time window is pretty short. First among them is 7M: a 7 MHz clock that’s provided by the Apple II. I examined what 7M was doing at the time of the glitches, but there was no particular phase relationship I could find between 7M and the Q3 glitch, after reviewing many example glitches. So I think 7M can be crossed off the list. Next is Phi1, another Apple II clock. But reviewing the trace showed that Phi1 never changes during the time period of interest.
That only left a couple of asynchronous signals as possibilities, including RDDATA, the incoming bit stream from the disk. RDDATA could change state at essentially any time. When I captured a trace including the glitch and RDDATA, I found something very interesting:

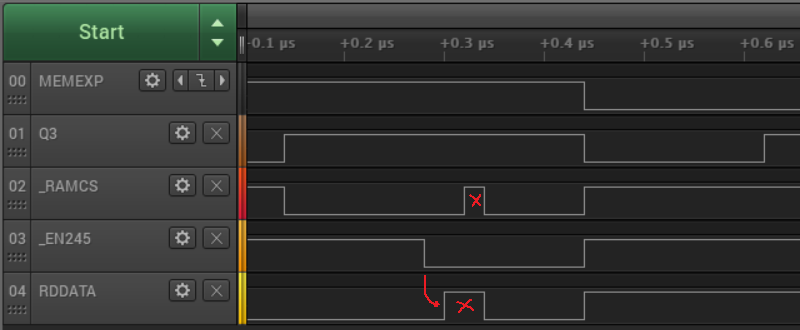
I call this the multi-glitch. You can see there’s a glitch on RDDATA before the falling edge of Q3, with a simultaneous glitch on RAMCS, and the glitch on Q3 happening about 140 ns after that. This tells a different story than my earlier data, because it shows that the problem started before the falling edge of Q3. It means the Q3 glitch is just a manifestation of something that went wrong a moment earlier.
At first I thought there was a simple explanation for this: something bad on RDDATA causing cascading problems elsewhere. But although a glitch on RDDATA would cause disk data to get corrupted, it shouldn’t have any effect on RAMCS or Q3. Instead I think all three signals must be getting impacted by sudden fluctuations in the power supply. At least that’s the only explanation I can think of for three signals to glitch at the same time, when they’re logically unrelated and physically separated on the PCB.
The glitching on RDDATA and RAMCS looked unrelated to the actual data on RDDATA, but it always happened about 160 ns after the rising edge of Q3. Applying the same armchair reasoning as before, I wondered what other signals might be changing state when the glitch occurred, and this time I had a better answer. That’s about 20 ns to 80 ns after the board’s 74LVC245 bus driver is enabled, pushing Yellowstone’s output byte onto the Apple II data bus:
Now I think we may finally be getting close to an answer. It would make a lot of sense to see sudden fluctuations in the power supply shortly after the 74LVC245 is enabled. If there’s bus contention, that’s the moment when it’s going to appear. And even if there’s not bus contention, if the bus driver’s outputs simultaneously all change from 0 to 1 or vice-versa, it can create a big current spike. This is exactly why bypass capacitors are important, to smooth out power supply noise from this type of event.
Bus contention on this ‘245 was exactly what caused the downfall of my original Yellowstone effort back in 2017-2018. It was more than two years before I came back to it, identified the bus contention, and fixed it. Or did I? Maybe it’s not completely fixed? So I tried making some changes to advance or delay the timing of the ‘245 enable signal, but it didn’t seem to have any effect on the glitching. Hmm.
Maybe there’s no bus contention, but it’s still a problem when all the bus driver’s outputs change at once. I’m not sure why that problem would only happen when the SRAM chip is being read, but maybe the SRAM also places a sudden load on the supply rail, and the combination of the two effects is too much. Do I have insufficient bypass capacitance on my ‘245 bus driver chip? It’s a 0.1 uF ceramic capacitor, connected by short traces to the chip’s power and ground pins. I could try soldering in some additional capacitors, or capacitors of a different type.
Whether it’s bus contention or something else causing power supply fluctuations, I ought to be able to see the fluctuations on the 3.3V supply at the moment of the glitch. But when I looked, I didn’t see anything. That could be because I used the analog mode of my logic analyzer, which has a very limited bandwidth, rather than a true oscilloscope. I need to keep looking. I feel like I’m getting closer to solving this puzzle, but still not quite there.
There’s still one other possible explanation here: a damaged chip resulting from my earlier fiasco when D5 was accidentally shorted to the 3.3V supply. That could have damaged the ‘245, the SRAM, or the FPGA. They all seem to be working OK now, but maybe there’s some hidden damage, and under the right conditions the ‘245 will go crazy and draw way too much current.
Read 1 comment and join the conversation1 Comment so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
Ah, this isn’t going well. I measured the 3.3V supply with a scope and saw some moderate bouncing when the ‘245 is enabled, but not so severe I’d expect problems. Anyway I tried hacking in an extra 0.01 uF bypass cap for the ‘245: glitch still occurs. Tried an extra 1.0 uF bypass cap: glitch still occurs. Desoldered the ‘245 and replaced it with a new one: glitch still occurs. Bah.