

When 64 Kbits Is Not 8 Kbytes
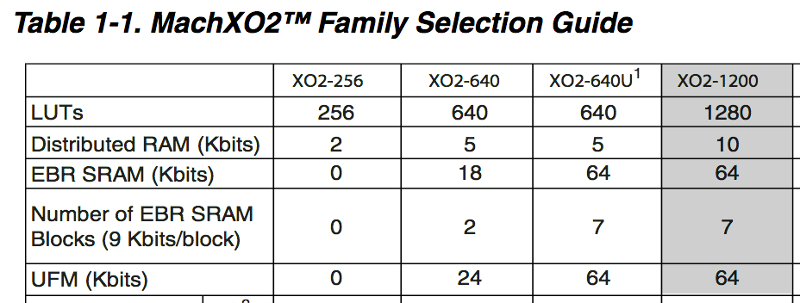
This FPGA-based disk controller project is going to need every byte of on-chip memory that I can scrounge up. The datasheet says my Lattice MachXO2-1200 has 64 Kbits of embedded RAM (EBR). See the shaded column in the table above. 64 Kbits is 8 Kbytes, and I plan to store 8 KB of 6502 program code, so that looks perfect. Except that I misinterpreted the table in two different ways.
Looking more closely at the table, there are 7 EBR blocks and each block is 9 Kbits. That’s a total of 63 Kbits, not 64. The datasheet is just wrong here, or they’re using some very liberal rounding method. I just lost 1 Kbit!
That’s not the worst of it. Later in the datasheet, it mentions that each EBR block can be configured as 8192 x 1, 4096 x 2, 2048 x 4, or 1024 x 9. Only the last of those configurations represents 9 Kbits of data. If you want to store 8-bit wide data, you have to use the 1024 x 9 configuration and throw away the extra bit. So that’s another 1 Kbit lost from each bank.
When you add everything up, if you’re storing 8-bit wide data, the MachXO2-1200 can only store 56 Kbits in EBR rather than the advertised 64 or 63 Kbits. That may sound like a small difference, but it will have a big impact on my design.
Sure I could add an external SRAM, and maybe I’ll do that eventually, but I really want to squeeze all the advertised memory space from this chip. The wasted area offends my engineering sensibilities. So I’ve been brainstorming a couple of crazy solutions, and wondering if anyone else has ever tried something similar.
I could pack the 8-bit byte data like a bitstream into consecutive 9-bit words of an EBR block, so nine bytes A through I would be stored in eight words:
EBR0[0]: B0 A7 A6 A5 A4 A3 A2 A1 A0 EBR0[1]: C1 C0 B7 B6 B5 B4 B3 B2 B1 EBR0[2]: D2 D1 D0 C7 C6 C5 C4 C3 C2 EBR0[3]: E3 E2 E1 E0 D7 D6 D5 D4 D3 EBR0[4]: F4 F3 F2 F1 F0 E7 E6 E5 E4 EBR0[5]: G5 G4 G3 G2 G1 G0 F7 F6 F5 EBR0[6]: H6 H5 H4 H3 H2 H1 H0 G7 G6 EBR0[7]: I7 I6 I5 I4 I3 I2 I1 I0 H7
To read a byte would require reading two separate words, and then doing some bit shifting and masking with the results. I’d need some kind of state machine and an appropriate clock to handle the two separate reads. And I’d need some kind of divide by nine logic (or eight-ninths?) to convert a byte-oriented address to the corresponding 9-bit word address.
A second idea is to leverage the fact that these are seven separate EBR blocks, and to read from them all in parallel, combining one or two bits from each to reassemble the byte:
EBR0[0]: I0 H0 G0 F0 E0 D0 C0 B0 A0 EBR1[0]: I1 H1 G1 F1 E1 D1 C1 B1 A1 EBR2[0]: I2 H2 G2 F2 E2 D2 C2 B2 A2 EBR3[0]: I3 H3 G3 F3 E3 D3 C3 B3 A3 EBR4[0]: I4 H4 G4 F4 E4 D4 C4 B4 A4 EBR5[0]: I5 H5 G5 F5 E5 D5 C5 B5 A5 EBR6[0]: E6 D7 D6 C7 C6 B7 B6 A7 A6
The intended advantage here was that I would only need to do one read from each EBR block, but since there are one fewer EBR blocks than bits in a byte, one of the blocks must perform double-duty and this advantage is lost. And I would still need some kind of divide by nine address logic, with different logic for some EBRs than others. I’m actually not sure whether this approach would even work.
I feel like there should be some not-too-complex scheme to store the full 63 Kbits of data in a way allowing for 8-bit byte retrieval, but I can’t quite find it.
Read 9 comments and join the conversation9 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
If you’re willing to use distributed RAM as well, you can use that to get the full 64 Kibit of data without any divisions or state machines:
words 0x0000..0x03FF: bits 7..0 from EBR 0
words 0x0400..0x07FF: bits 7..0 from EBR 1
words 0x0800..0x0BFF: bits 7..0 from EBR 2
words 0x0C00..0x0FFF: bits 7..0 from EBR 3
words 0x1000..0x13FF: bits 7..0 from EBR 4
words 0x1400..0x17FF: bits 7..0 from EBR 5
words 0x1800..0x1BFF: bits 7..0 from EBR 6
words 0x1C00..0x1FFF: bit 8 from EBRs 6..0, one extra bit from distributed RAM
That requires 1024 distributed RAM bits or 10 % of the total resources, which sounds reasonable to me.
Oh, and if you really need ROM, not RAM, I’ve found that just encoding the ROM as a huge select statement in VHDL (or probably verilog) gives surprisingly good results because then the synthesis tool can “compress” it by logic optimization.
You could even experiment to see which 1024 bits of your desired ROM contents are most compressible.
Nice! Yes that sounds like a good solution. I also thought of another general solution for storing 9 Kbits of byte-oriented data in a single EBR without any need to perform division. It’s a small change to the first scheme I described above. Bytes A through H are bytes 0 through 7 logically, but then byte I is logical byte 1024. Following that are logical bytes 8-15 and then 1025. The pattern repeats with eight more bytes always followed by one out-of-sequence byte. This would enable storing 1152 bytes in a 9 Kbit EBR, with one addressing scheme for bytes 0-1023 and a different scheme for 1024-1151, but both schemes use powers of two and don’t require any divisions to find the word address. But it still requires reading two 9-bit words to reconstruct a single byte.
I love the “compression” idea. I will try it and see how much it helps. Here’s an interesting detail: If I understand the MachXO2 datasheet, the number it advertises for distributed RAM is specifically for *RAM*. A distributed *ROM* is implemented differently and can store twice as many bits. I don’t exactly understand the reasons, but in each 4-slice “Programmable Function Unit”, only slices 0 and 1 can be used as distributed RAM but all of slices 0 through 3 can be used as distributed ROM.
Yes, your scheme for 1152 should work. You could probably move some bits around to reduce the amount of multiplexing needed at the output. At the moment, every bit of a logical 8-bit output word can come from any bit of the physical 9-bit EBR words, which is not optimal.
You could also use both ports of the EBR to read both words at the same time. Or, if you have multiple EBRs, there should be some clever arrangement where the required words always come from two different EBRs.
For RAM, I think it’s mostly a trade-off because RAM support requires some extra transistors in the FPGA. Using all LUTs as RAM is not really useful because then there would be no room for other logic. Also, while normal operation requires just 4 input bits for each LUT, a RAM needs 4 read address bits, 4 write address bits, and a write enable and write data bit. My best guess is that in RAM mode, slices 0 and 1 operate normally (so their inputs are the read address and you could in principle read from different addresses in each LUT, and you can use the flip-flop if so desired), while slice 2 has the write address, enable and data signals.
Of course ROM mode does not differ at all from normal operation. Each LUT is already a 16×1 ROM, and you can use the LUT5 MUX to implement a 32×1 ROM from two LUTs. Anything deeper will require additional LUTs used as multiplexers.
Oh, I forgot the write clock signal, so a 4-bit RAM needs 11 inputs.
And they actually tell you the assignment right in the datasheet:
> For Slices 0 and 1, memory control signals are generated from Slice 2 as follows:
> • WCK is CLK
> • WRE is from LSR
> • DI[3:2] for Slice 1 and DI[1:0] for Slice 0 data from Slice 2
> • WAD [A:D] is a 4-bit address from slice 2 LUT input
That pretty much confirms my theory: The 4 bits of write data are the inputs of one of the LUTs in slice 2, the 4 bits of write address are the inputs of the other LUT, and the write clock/enable are the inputs that would normally control the registers in slice 2. Slice 3 is not used at all and is available for unrelated logic.
I hate to be the one to say this… but maybe get a bigger FPGA (ducks)
I totally agree and suggested something along these lines as a comment to an earlier post.
FPGAs are way too cool, especially for future upgrades that were not even considered when designing the hardware, to limit oneself by using a device that’s barely enough for the current use case.
Any reason to not at least use the XO2-2000, also available in a TQFP-100 package?
I cannot argue against the lattice fpga devices. The open-source toolchain and community support really helps.
BTW, ended up reading about the new Raspberry Pi PICO device today. You should check out the PIO units on this device. They have WOZ machine vibes.
I’m in the midst of building another prototype using an XO2-2000, but it only offers 8 block RAMs instead of 7, so it’s not a big improvement. If I can squeeze the final design into the XO2-1200 with a bit of effort, it’s worth it to me. I think I probably can. The -1200 has better parts availability and cheaper price. I agree with the general idea of “future-proofing” where it’s practical, but I wouldn’t want to commit to a less-desirable FPGA just because of some vague possibility of unspecified future upgrades.
The open source Lattice toolchain is interesting from a tech perspective. I wouldn’t be comfortable relying on it, though, and I’m not sure why I’d want to. I guess it would be nice to run the tools on non-Windows machines and to skip the “free but licensed” hassles, but those are small benefits. FPGAs are fantastically complex devices, and I don’t know how anyone but the vendor could create accurate tools for determining things like internal propagation delays or power or other small but critical details. For all we know, the vendor tools might apply custom rules when placing and routing to work around bugs or limitations in the FPGA silicon.
I admit I’ve spent (wasted?) quite a lot of time evaluating different FPGAs to see if there’s something better I could be using. The MachXO2 family is about 10 years old, so surely there must be something better or cheaper or both? But when I limit the FPGA search to parts at a similar price point to MachXO2 and with at least 2K of RAM and at least ~44 user I/Os and that are available in a reasonable package, there aren’t many options that look better. Reasonable package means not BGA, and 100 pins or fewer. MachXO2 is the *only* option that meets all those requirements. If I’m willing to go to a 144 pin chip, then there are a few other options like the Altera (Intel) MAX10, but they aren’t different enough from the MachXO2 to justify the effort needed to switch. If I’m willing to use BGA packages, then lots of interesting options become available. But I have no experience with BGA, and don’t really want to try it just now. Maybe someday for a different project.