

Archive for March, 2010
128 Is Not Enough
With more work, I was able to further squeeze the design down to 77 macrocells! You can grab the latest version of the Verilog files here.Unfortunately, when I then started to add the X register and its related functionality, things turned ugly very quickly. Even just adding an X register that could be loaded and stored, incremented and decremented, ballooned the macrocell count to 111. I went back and forth over it several times, trying various optimizations. I even tried doing a major reorganization of the whole design, moving all the math ops to the ALU, and introducing explicit datapaths instead of relying on Verilog to infer them, but nothing helped too much. And I can’t really go all the way to 128 macrocells anyway, due to routing congestion and other constraints. Even the 111 macrocell version does not actually fit the Max 7128.I’m still going to try a few other changes to see if I can improve the resource usage enough, but I know that adding indexed addressing and a stack is going to require lots more resources, so I’d likely just be postponing the inevitable. I think I will end up with three choices:
- Be satisfied with what I have now, add a few more little things, and call it done. That would mean giving up indexed addressing and a stack, making the CPU far less capable.
- Start over from scratch with a new, detailed design that accounts for exactly how it will be synthesized. Essentially, compute by hand the logic equations that should be implemented in each macrocell, so I can know exactly what’s happening and where the resources are going, and hope to use them more efficiently.
- Drop the idea of a 6502-lite CPU, and implement some entirely different design with a simpler architecture, like a stack machine.
At the moment, none of those options really appeal to me. We’ll see…
Read 3 comments and join the conversation8-Bit CPU Comparison
BMOW’s instruction set was a close cousin to the 6502’s, and so when I started on CPLD CPU, I initially intended to try something different. I looked at the Intel 8008 and 8080, Zilog Z80, and Motorola 6800 and 6809, which were all popular 8-bit CPUs back in the 1970’s and 80’s. After studying up on the architecture of all these different CPUs, I decided that the 6502 was still the best choice to use as a model, because I believe it can be implemented using the least CPLD resources.
The cross-CPU comparisons were very interesting. The key differences between these early 8-bit CPUs fell into four main areas: number of data registers, 16-bit instruction support, address registers, indexed addressing.

Number of Data Registers
More registers are just about always better, except where you’re starved for logic resources in a tiny CPLD. While the 6502 has three 8-bit registers A, X, and Y, my plan is to only include A and X in the CPLD CPU instruction set.
CPU 8-Bit Data Registers:
- 8008 – 7, ABCDEHL
- 8080 – 7, ABCDEHL
- Z80 – 7, ABCDEHL
- 6800 – 2, AB
- 6809 – 2, AB
- 6502 – 3, AXY
16-bit Extensions
While all the CPUs in this group are 8-bit designs, some support a limited number of 16-bit operations too. These are very handy for the programmer, but any 16-bit operation can also be performed as a series of 8-bit operations, so the difference is one of speed and not capability.
CPU 16-bit Support:
- 8008 – none
- 8080 – BC, DE, HL can be joined to form 16-bit registers. They support load/store of 16-bit values, and increment/decrement. Addition/subtraction of 16-bit registers is supported when HL is used as an accumulator.
- Z80 – Same as 8080, with some added flexibility on supported operations.
- 6800 – none
- 6809 – AB can be joined to form a 16-bit register D. It supports load/store of 16-bit values, and addition/subtraction/compare with a 16-bit value in memory.
- 6502 – none
Address Registers
Most modern CPUs store an address in a user-visible register, then use other instructions to manipulate the data at that address. These may be registers used specifically for holding addresses, or general purpose data/address registers, but either way the size of the register must be at least as large as the address space of the CPU. For example, the 8008 and 8080 have the M register, which can hold a 16-bit address. A byte can then be fetched from that address into the accumulator with the instruction MOV A,M. This is convenient, because you can do things like perform arithmetic on M in order to construct the right address for a value in a struct.
Another way of approaching addresses is to include them directly in the instruction itself. For example, the 6502 can fetch a byte from address $0123 into the accumulator with the instruction LDA $0123. This has the advantage that you don’t have to load $0123 into an address register first, but it means you can’t do arbitrary arithmetic on the address.
A CPU that supports absolute addresses directly in the instruction must have a hidden, temporary address register. That address in the program code has to be loaded somewhere, so that it can then drive the address bus, and a user-hidden address register fits the bill nicely.
In a CPLD CPU, the user-visible and user-hidden address registers both require space: one macrocell per bit. 10 macrocells for an address register is expensive, when your entire device only has 128. Having only a user-visible address register creates a fairly clunky programming experience, because it rules out having absolute addresses in the instruction, and forces the programmer to manually load the address register first before every memory reference. This is what the 8008 does. Most CPUs have both. The 6502 is unique in this group by having only a hidden address register, and no user-visible one. This gives up some flexibility, but is still a workable solution and eliminates one large register from the CPLD. The 6502’s zero page mode can also turn the first 256 bytes of memory into 128 pseudo-address registers.
CPU Has a User-Visible Address Register?
- 8008 – Yes, HL (also called M). ALL memory references must be done with this (no absolute addressing). Must load L and H separately.
- 8080 – Yes, BC, DE, HL. Can swap DE<->HL. Also supports absolute memory addresses.
- Z80 – Yes, Same as 8080. Adds some additional flexibility for addressing modes.
- 6800 – Yes, has a 16-bit X register. This functions like an address register when used with a absolute base address of 0. Only limited support for arithmetic with X. Also supports absolute memory addresses.
- 6809 – Yes, has 16-bit X and Y registers. Otherwise same as 6800.
- 6502 – No. Supports absolute memory addresses, and page 0 of memory as a set of pseudo-address registers.
Indexed Addressing
A very common pattern in assembly language programming is to reference a memory location using a combination of a base address and an offset. When performing some operation to many consecutive memory locations, this is generally faster and more convenient than altering the base pointer each time through the loop. For example, the 6502 can load a byte to the accumulator at some offset from address $0123 with the instruction LDA $0123,X. This takes the value currently in the X register, adds it to $1023, and uses the resulting address as the location from which to load a byte. Here’s an example 6502 programming using indexed addressing to sum all the values in memory locations $1000 to $100F:
ldx #$0F ; initialize X index
lda #$00 ; register A holds sum, initialize to 0
clc ; clear carry flag
- adc $1000,X ; add the byte from memory to the running total
dex ; decrement X index
bpl - ; if index is >= 0, branch to start of loop and keep going
Not all those early 8-bit CPUs supported indexed addressing. For CPUs with a user-visible address register, it’s not strictly necessary, because the programmer can accomplish a similar result by doing arithmetic on the value in the register. But even where it’s not necessary, it’s still a very handy feature. The 6502 supports indexed addressing in the most resource-efficient manner of the CPUs in this group.
CPU Supports Indexed Addressing?
- 8008 – No, must manipulate the address register manually.
- 8080 – No, must manipulate the address register manually.
- Z80 – Yes, uses two 16-bit address registers, and an 8-bit offset that’s part of the instruction.
- 6800 – Yes, uses one 16-bit address register, and an 8-bit offset that’s part of the instruction.
- 6809 – Yes, uses two 16-bit address registers, and an 8-bit offset that’s part of the instruction.
- 6502 – Yes, uses one 8-bit offset register, and a 16-bit address that’s part of the instruction.
T-Shirts
 BMOW logo T-shirts are now available! Check the link on the left sidebar. Get one and show a little electronics geek pride! Available in six colors, $18.99 each, operators are standing by to take your order.
BMOW logo T-shirts are now available! Check the link on the left sidebar. Get one and show a little electronics geek pride! Available in six colors, $18.99 each, operators are standing by to take your order.
These are the same T-shirts that I and my assistants wore at the Maker Faire last year, where many visitors were disappointed they couldn’t buy a shirt for themselves. I only made six in that first run, but my friends who got them still seem to wear them a lot (maybe a little TOO much). I wore one at Disneyland last year, which led to a long conversation about CPU design with a guy I met while in line for Mr. Toad’s Wild Ride. Electronics geeks are everywhere.
Feeds
If you’re not reading the BMOW comments, you’re missing half the discussion. Matthew Simmons asked if there’s a comments feed, and the answer is YES. I’ve added links for both the posts and comments feeds to the left sidebar. I often make follow-up comments to my own posts, with progress updates or related discoveries, and lots of smart people provide great suggestions and commentary. If you normally read the BMOW site with an RSS reader, be sure to add the comments feed too so you don’t miss out.
Be the first to comment!Birth of a CPU
I’ve finished the basic guts of the CPLD CPU, and it works! It’s still missing roughly half of the intended CPU functionality, but what’s there now is still a usable CPU. I’ve implemented jumps, conditional branching, set/clear of individual ALU flags, bitwise logical operators, addition, subtraction, compare, and load/store of the accumulator from memory. The logical and mathematical functions support immediate operands (literal byte values) as well as absolute addressing for operands in memory. Not too shabby! Not yet implemented are the X register, indexed addressing, the stack, JSR/RTS, increment, decrement, and shift.
I wrote a verification program to exercise all the instructions in all the supported modes, which I re-run after every design change to make sure I didn’t break anything. Here’s a screenshot of the verification program in ModelSim, which doesn’t really demonstrate anything useful, but looks cool. You can grab my Verilog model, testbench, and verification program here. Comments on my Verilog structure and style are welcome.

Now for the bad news. The design has consumed far more CPLD resources than I’d predicted. I’m targeting a 128 macrocell device, but the half-finished CPU I’ve got now already consumes 132. By the time it’s done, it might be twice that many. While I think my original accounting of macrocells needed for registers and state data was accurate, it looks like I greatly underestimated how many macrocells would be required for random logic. For example, after implementing the add instruction, the macrocell count jumped by 27! That’s almost 25% of the whole device, for a single instruction.
I’m finding it difficult to tell if the current macrocell total is high because I’m implementing a complex CPU, or because I’m implementing a simple CPU in a complex way. Could I get substantial macrocell savings by restructuring some of the Verilog code, without changing the CPU functionally? It’s hard to say, but I think I could. Looking at the RTL Model and Technology Map View is almost useless– they’re just incomprehensible clouds of hundreds of boxes and lines. Yet deciphering these is probably what I need to do, if I want to really understand the hardware being synthesized from my Verilog code, and then look for optimizations.
The Verilog code is written in a high-level manner, specifying the movement of data between CPU registers, but without specifying the logic blocks or busses used to accomplish those movements. These are left to be inferred by the synthesis software. For example, the add, subtract, and compare instructions could conceivably all share a single 8-bit adder. So do they? The Verilog code doesn’t specify, but I think the synthesis software inferred separate adders. On the surface this seems bad, but I learned in my previous experiments that the software is generally smarter than I am about what logic structures to use. Still, I’ll try restructuring that part of the code to make it clear there’s a single shared adder, and see if it helps or hurts.
The core of the code is a state machine, with a long always @* block implementing the combinatorial logic used to determine the next values for each register, each clock cycle. There are 10 unique states. The clever encoding of the 6502’s conditional branching and logic/math opcodes (which I’m following as a guide) allowed me to implement 24 different instructions with just a handful of states.
Verilog NOT Operator, and Order of Operations
I encountered a mystery while working on the CPU design. I attempted to aid the synthesis software by redefining subtraction in terms of addition:
{ carryOut, aNext } = a + ~dataBus + carryIn;
This works because a – b is the same as a + not(b) + 1. If carryIn is 1, then subtraction can be performed with an adder and eight inverters. Fortunately the CPLD already provides the normal and inverted versions of all input signals, so the bitwise NOT is effectively free. I was very surprised to find that the above code does not work! It computes the correct value for aNext, but carryOut is wrong. The following code, however, does work as expected:
{ carryOut, aNext } = a + {~dataBus[7], ~dataBus[6], ~dataBus[5], ~dataBus[4], ~dataBus[3], ~dataBus[2], ~dataBus[1], ~dataBus[0]} + carryIn;
Now how is that second line different from the first? I would have said they were completely equivalent, yet they are not. The difference seems to be some subtlety of Verilog’s rules for sign-extending values of different lengths when performing math with them.
Even stranger, I found that the order in which I listed the three values to be summed made a dramatic difference. Hello, isn’t addition associative? Apparently not, in the bizarro world of Verilog:
{ carryOut, aNext } = a + ~dataBus + carryIn; // design uses 131 macrocells
{ carryOut, aNext } = carryIn + a + ~dataBus; // design uses 151 macrocells
{ carryOut, aNext } = carryIn + ~dataBus + a; // design uses 149 macrocells
Read 8 comments and join the conversation
Separated at Birth
I’ve been planning to use an Altera Max 7128S for this CPLD – CPU project, because at 128 macrocells it’s the largest commonly-available CPLD that I could find in a PLCC package. Yesterday, however, I started wondering how the competition from Xilinx stacked up. Even if I couldn’t get as large a device (108 macrocells max in a PLCC package), maybe the Xilinx device architecture allowed for denser logic, more product terms per macrocell, or some other factor that might permit it to do more with less. So I read through the details of the Xilinx XC95108 CPLD datasheet, comparing it to the Altera EPM7128S CPLD, to see how they differed.
What I found nearly made me laugh out loud. They are the same. Not just similar, but virtually identical in their internal architectural details. All the marketing terms and sales claims make it sound as if each vendor has some amazing technological advantage, but it’s all just hype. Inside, when you look at how these devices work internally, there’s no meaningful difference I could find. What’s more, the descriptive text of the two datasheets is so similar, if this were a school project, they’d be hauled in front of the disciplinary committee on plagiarism charges.
Take a look at the Altera diagram of one of their macrocells. You’ve got a logic array on their left with 36 inputs, five product terms feeding into a selection matrix. Additional product terms from other macrocells can also feed into the matrix if needed. The output goes to set of OR/XOR gates, and then either to a flip-flop, or bypasses the flip-flop and exits the macrocell. Product terms can also be used as clock, preset, clear, and enable control signals for the flip-flop, or global signals can be used for those controls.

Now take a look at the diagram of a Xilinx macrocell. Look familiar? 36-Entry logic array, five product terms, optional expansion terms from other macrocells, OR/XOR gates, flip-flop with bypass, and choice of product terms or global signals for clock, preset, clear, and enable. It’s almost an exact copy of the first diagram. It’s like a children’s game of “find five differences between these pictures”.
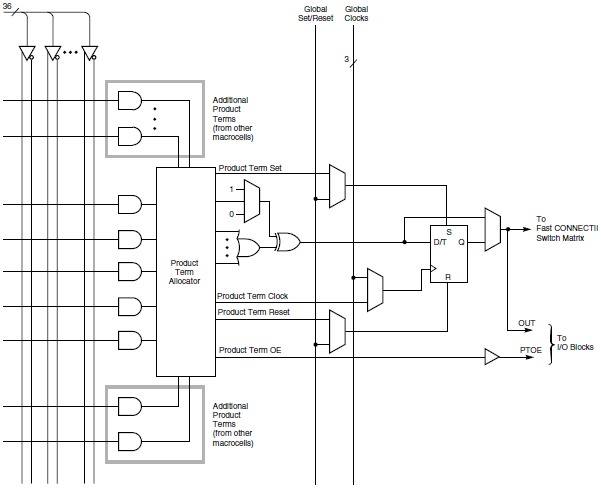
OK, there are some minor differences, like Altera’s “expander” product terms, and the exchange of a clock enable for an output enable signal. But you have to admit these diagrams are so similar, they could have been made by the same person. They even make the same arbitrary choices for orientation and position of the elements in the diagram.
Now compare the accompanying text. First, Altera’s: “Combinatorial logic is implemented in the logic array, which provides five product terms per macrocell. The product-term select matrix allocates these product terms for use as either primary logic inputs (to the OR and XOR gates) to implement combinatorial functions, or as secondary inputs to the macrocell’s register clear, preset, clock, and clock enable control functions.”
And here’s Xilinx’s text: “Five direct product terms from the AND-array are available for use as primary data inputs (to the OR and XOR gates) to implement combinatorial functions, or as control inputs including clock, set/reset, and output enable. The product term allocator associated with each macrocell selects how the five direct terms are used.”
Don’t those seem more than just a little bit similar? I mean, there’s a long clause that’s almost word-for-word identical, including the choice to use a parenthetical expression: “for use as [either] primary [logic/data] inputs (to the OR and XOR gates) to implement combinatorial functions, or as [secondary/control] inputs”. That can’t be a coincidence.
Read 2 comments and join the conversation